更多>>关于我们
 西安鲲之鹏网络信息技术有限公司从2010年开始专注于Web(网站)数据抓取领域。致力于为广大中国客户提供准确、快捷的数据采集相关服务。我们采用分布式系统架构,日采集网页数千万。我们拥有海量稳定高匿HTTP代理IP地址池,可以有效获取互联网任何公开可见信息。
西安鲲之鹏网络信息技术有限公司从2010年开始专注于Web(网站)数据抓取领域。致力于为广大中国客户提供准确、快捷的数据采集相关服务。我们采用分布式系统架构,日采集网页数千万。我们拥有海量稳定高匿HTTP代理IP地址池,可以有效获取互联网任何公开可见信息。
 您只需告诉我们您想抓取的网站是什么,您感兴趣的字段有哪些,你需要的数据是哪种格式,我们将为您做所有的工作,最后把数据(或程序)交付给你。
您只需告诉我们您想抓取的网站是什么,您感兴趣的字段有哪些,你需要的数据是哪种格式,我们将为您做所有的工作,最后把数据(或程序)交付给你。
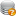 数据的格式可以是CSV、JSON、XML、ACCESS、SQLITE、MSSQL、MYSQL等等。
数据的格式可以是CSV、JSON、XML、ACCESS、SQLITE、MSSQL、MYSQL等等。
更多>>技术文章
更多>>官方微博
-
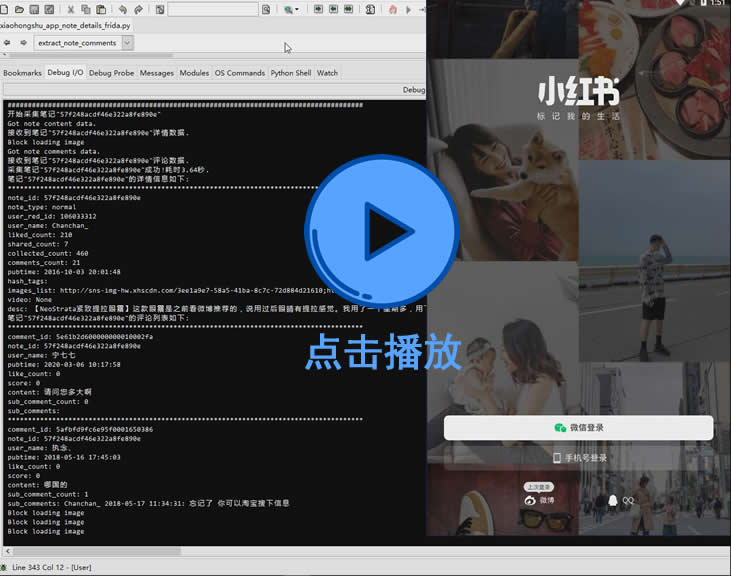
【经验分享】关于彻底关闭Nox模拟器虚拟机
背景: 命令行关闭Nox虚拟机可以使用"NoxConsole.exe quit <-name:nox_name | -index:nox_index>", 但是有时候会失败。
这里采用一种保险的思路,先调用"NoxConsole.exe quit"进行安全关闭,若干秒后检测虚拟机对应虚拟机的Nox.exe进程(考虑到多开的情况,根据"-clone:"参数判断是否属于当前虚拟机实例)和NoxVMHandle.exe进程(考虑到多开的情况,根据"--comment"参数判断是否属于当前虚拟机实例)是否还存在,如果存在就强制终止这两个进程,达到彻底关闭的目的。
完整实现如下图所示。发布时间:2021-11-02 10:16:20
-
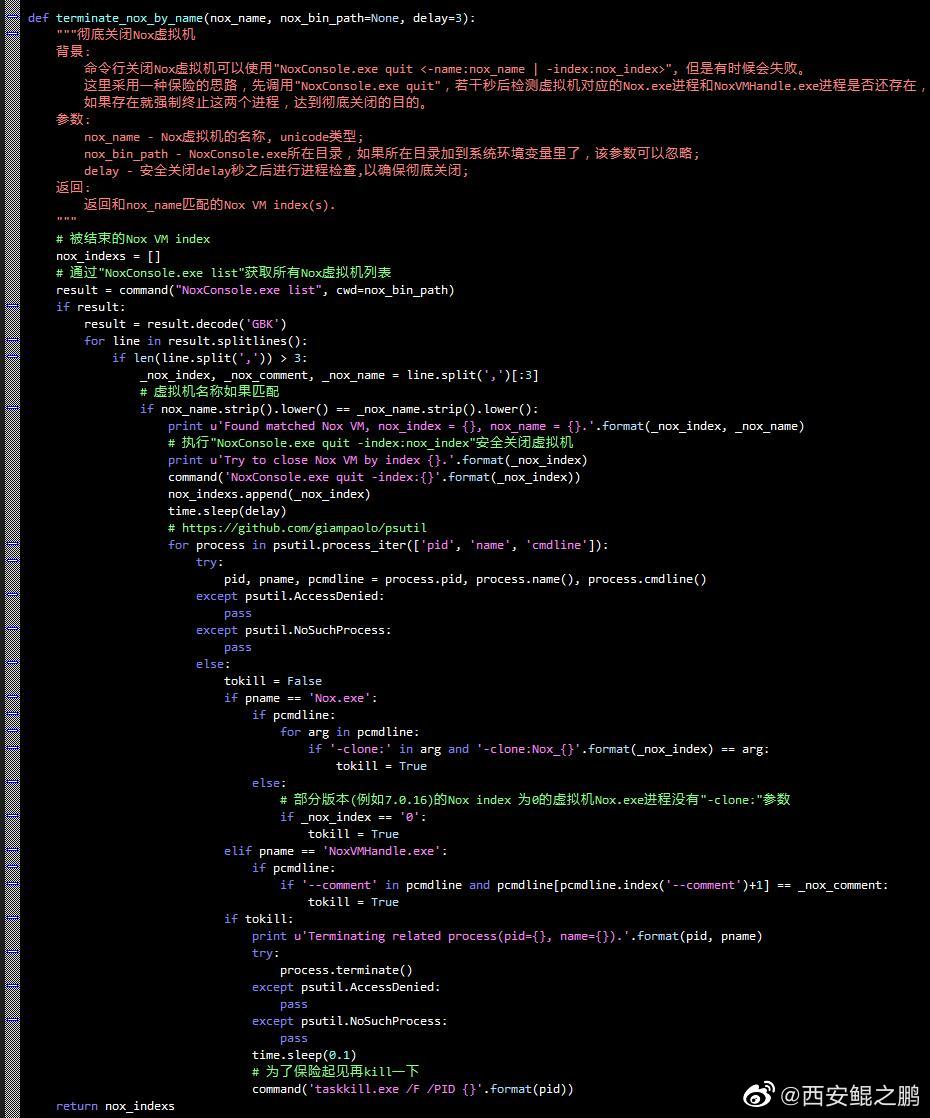
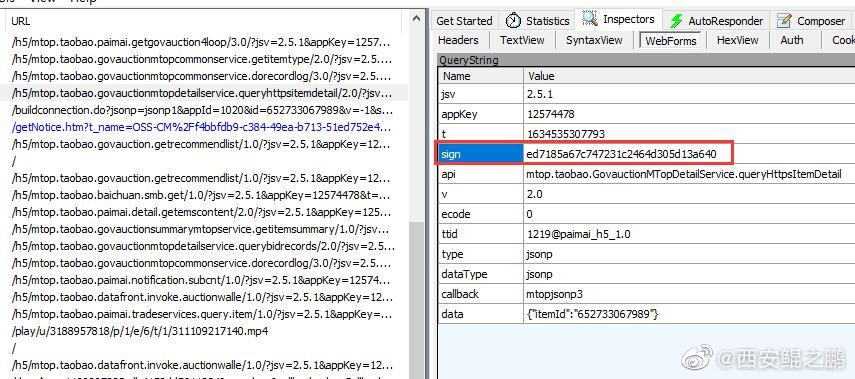
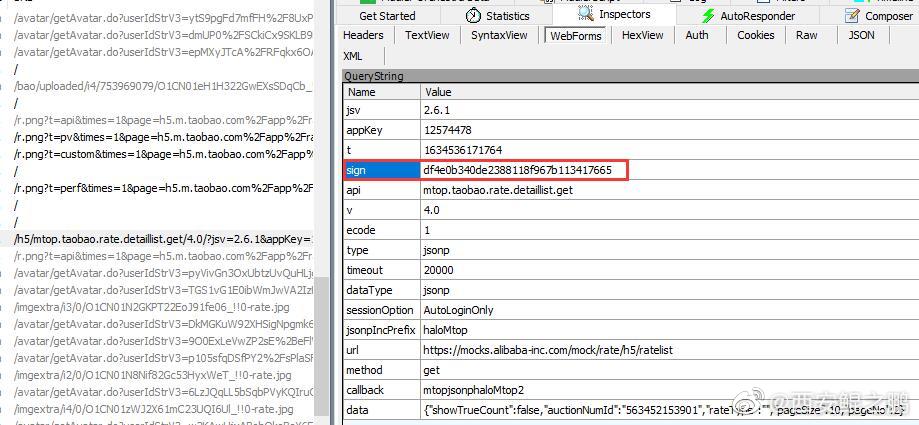
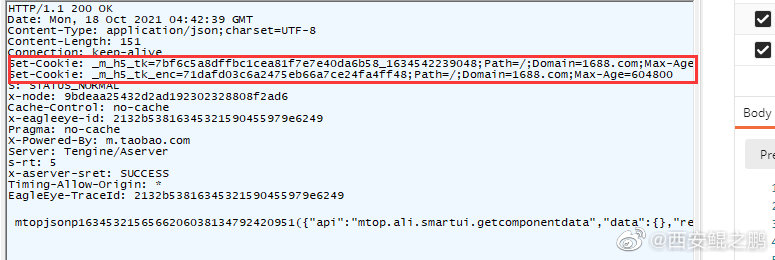
【经验分享】如何计算阿里系Ajax请求中的sign签名?
有过阿里系采集经验的开发者都应该知道,淘宝(天猫)H5版、1688、淘宝司法拍卖H5版等阿里系网站,在Ajax请求中都会有一个sign签名参数(如下图1、2、3所示),要是值不正确将无法获取到有效的数据(例如返回“非法请求”提示)。如果我们无法构造出有效的sign,就只能通过“模拟浏览器操作”的方式来绕过签名验证,再结合"mitmproxy动态抓包脚本"来提取返回数据,这种方案效率太低,而且很不灵活。本文将介绍如何计算这个sign值以及给出对应的Python实现,这样就能实现通过直接HTTP交互抓取数据。点击链接查看详情>>> http://www.site-digger.com/html/articles/20211018/851.html发布时间:2021-10-18 14:59:23
-
【经验分享】mysqldump时的两点技巧
(1)如何避免锁表?
加上--single-transaction=TRUE参数即可。
来源:https://stackoverflow.com/questions/104612/run-mysqldump-without-locking-tables
(2)如何排除某张表?例如 避免导出尺寸太大的日志表。
使用--ignore-table=dbname.tablename指定即可,如果要排除多个,加上多个--ignore-table=dbname.tablename参数。
来源:https://www.cnblogs.com/rxbook/p/7735485.html发布时间:2021-10-09 11:40:29
-
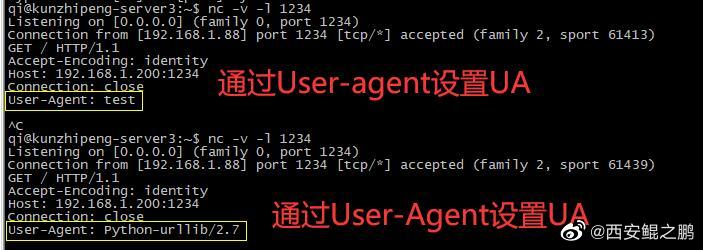
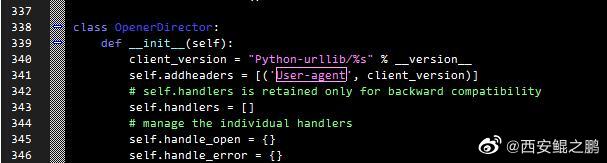
【经验分析】urllib2使用"User-Agent"设置UA会无效原因的分析
(1)如下代码,尝试使用"User-Agent"设置UA为"test",会失败:
服务端接收到的UA信息为"Python-urllib/2.7",而不是"test"。
urllib2.build_opener().open(urllib2.Request(url='http://192.168.1.200:1234', data=None, headers={'User-Agent': 'test'}))
(2)将headers修改为{'User-agent': 'test'},成功。
如附图1所示。原因是什么呢?
可以在urllib2.py中找到答案:
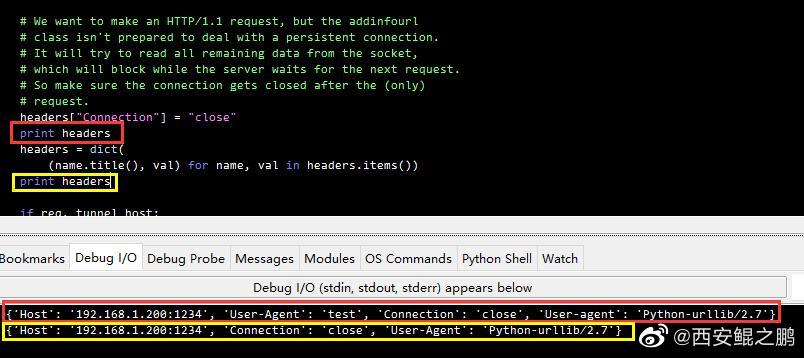
(1)首先urllib2默认会在headers列表中添加一个“User-agent”,其值为"Python-urllib/%s" % __version__,如附图2所示。
(2)在do_open()中对headers进行了规范化处理(.title()),代码如下。
headers = dict((name.title(), val) for name, val in headers.items())
如图3所示,我们在该句前后分别打印headers,处理之前为:
{'Host': '192.168.1.200:1234', 'User-Agent': 'test', 'Connection': 'close', 'User-agent': 'Python-urllib/2.7'},里面有我们设置的'User-Agent': 'test'
处理之后就变成下面了:
{'Host': '192.168.1.200:1234', 'Connection': 'close', 'User-Agent': 'Python-urllib/2.7'}
原因是后面的'User-agent'经过.title()后也会变'User-Agent',在字典中覆盖掉了我们自定义的值。
以后使用urllib2要设置UA时,一定要用“User-agent”,而不能用“User-Agent”!发布时间:2021-08-15 13:48:07
-
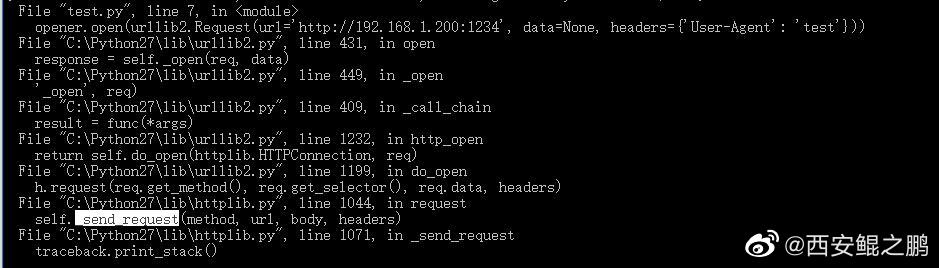
【经验分享】在分析别人代码的时候,通过打印调用栈可以帮助我们快速掌握调用函数的上下文调用逻辑。Python中如何打印调用栈呢?如下。
import traceback
traceback.print_stack()
参考>>> https://stackoverflow.com/questions/1156023/print-current-call-stack-from-a-method-in-python-code
例如,我们想知道httplib.py中_send_request()函数的调用上下文,在_send_request()中加入上述代码,当代码执行的时候就会在控制台打印出调用栈信息,如附图所示。发布时间:2021-08-15 13:17:33
-
【经验分享】如何给python函数增加一个timeout功能?
想要实现的效果:
在调用一个函数(不固定)的时候如果在指定的N秒内没有返回,就强制停止。
在github上找到了一些方案例如func_timeout,timeout_decorator。经过测试对比,func_timeout比较理想,项目主页:github.com/kata198/func_timeout,“Python module to support running any existing function with a given timeout.”。它提供了一个装饰器func_set_timeout,非常方便。
timeout_decorator原理:
它是利用子线程StoppableThread来执行目标函数,当指定时间到达,子线程还未结束,就强制结束子线程,然后抛出FunctionTimedOut异常,详见github.com/kata198/func_timeout/blob/master/func_timeout/dafunc.py。发布时间:2021-06-24 14:11:26
-
【演示】得物APP商品"最近购买列表"采集演示
(1)根据商品的spuid从APP端采集。
(2)得物的“最近购买”列表展示了最近3个月的销售记录,可以借以分析商品的价格和销量波动情况。包括字段“昵称、日期、规格、价格”,采集好的示例数据见:http://db.site-digger.com/csv/646577755f6170705f70726f647563745f6c6173745f736f6c645f6c6973745f73616d706c65/ 点击查看西安鲲之鹏的微博视频 发布时间:2021-06-24 13:17:22
-
【演示】某小红书APP笔记详情及评论数据采集最新(20210618)演示
近日某小红书的网页版不再展示笔记的“点赞数、评论数、收藏数和分享数”了,为了能拿到这些信息只能从APP端入手。本采集方案可以拿到笔记的所有属性值以及前10条评论数据。
(1)笔记详情包含的字段
'note_id'(笔记ID), 'note_type'(笔记类型,是普通的还是视频), 'user_red_id'(用户ID), 'user_name'(用户名), 'liked_count'(点赞数), 'shared_count'(分享数), 'collected_count'(收藏数), 'comments_count'(评论数), 'pubtime'(笔记发布时间), 'hash_tags'(标签), 'images_list'(原图列表), 'video'(视频链接,如果是视频笔记), 'desc'(笔记内容)
示例数据链接:点击查看"小红书笔记示例数据"
(2)笔记评论包含的字段
'comment_id'(评论), 'note_id'(关联的笔记ID), 'user_name'(用户名), 'pubtime'(评论发布时间), 'like_count'(评论点赞数), 'score'(评分), 'content'(评论内容), 'sub_comment_count'(评论回复数), 'sub_comments'(评论回复内容)
示例数据链接:点击查看小红书评论示例数据
发布时间:2021-06-18 14:30:34
-
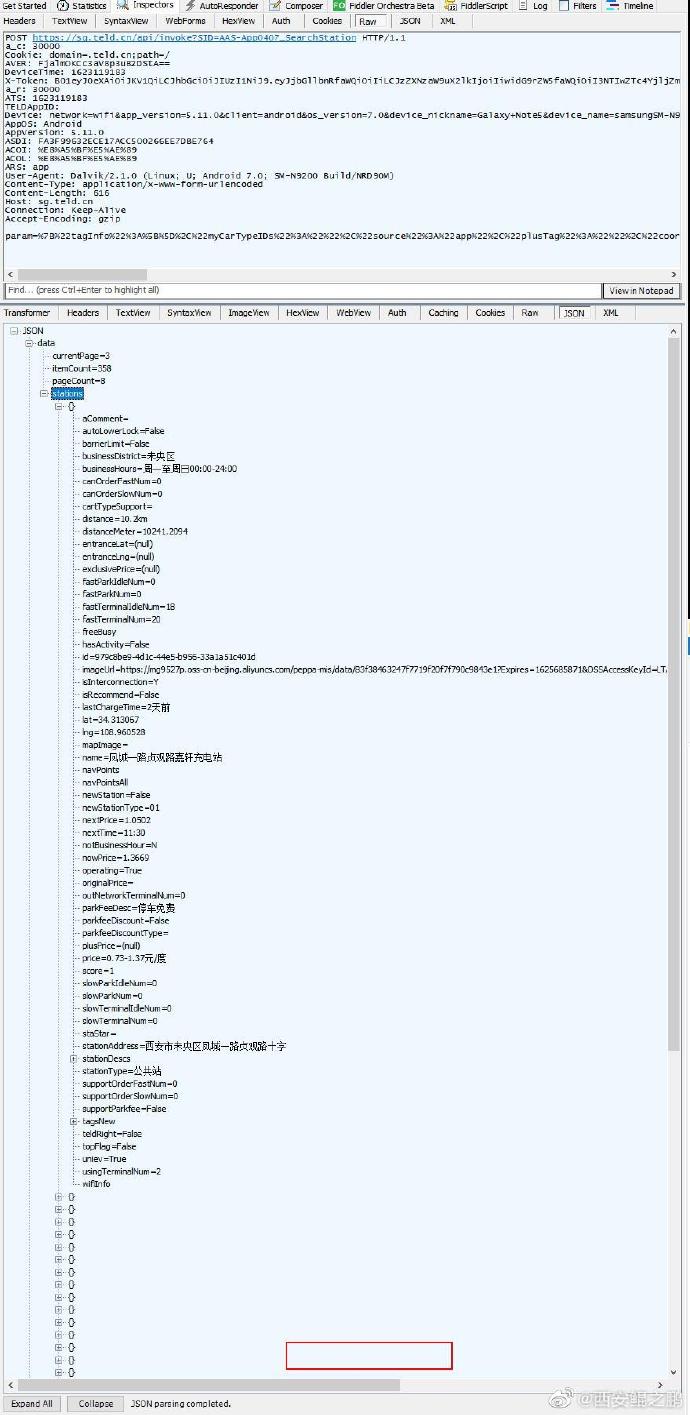
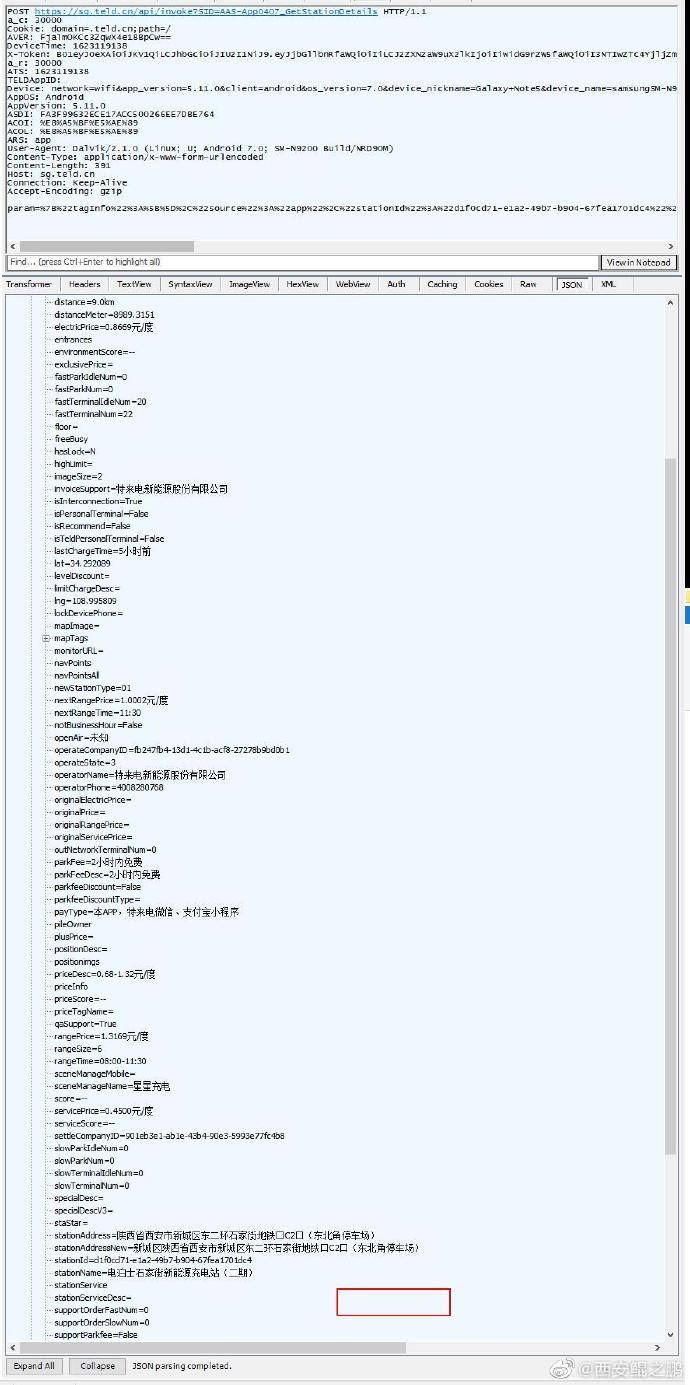
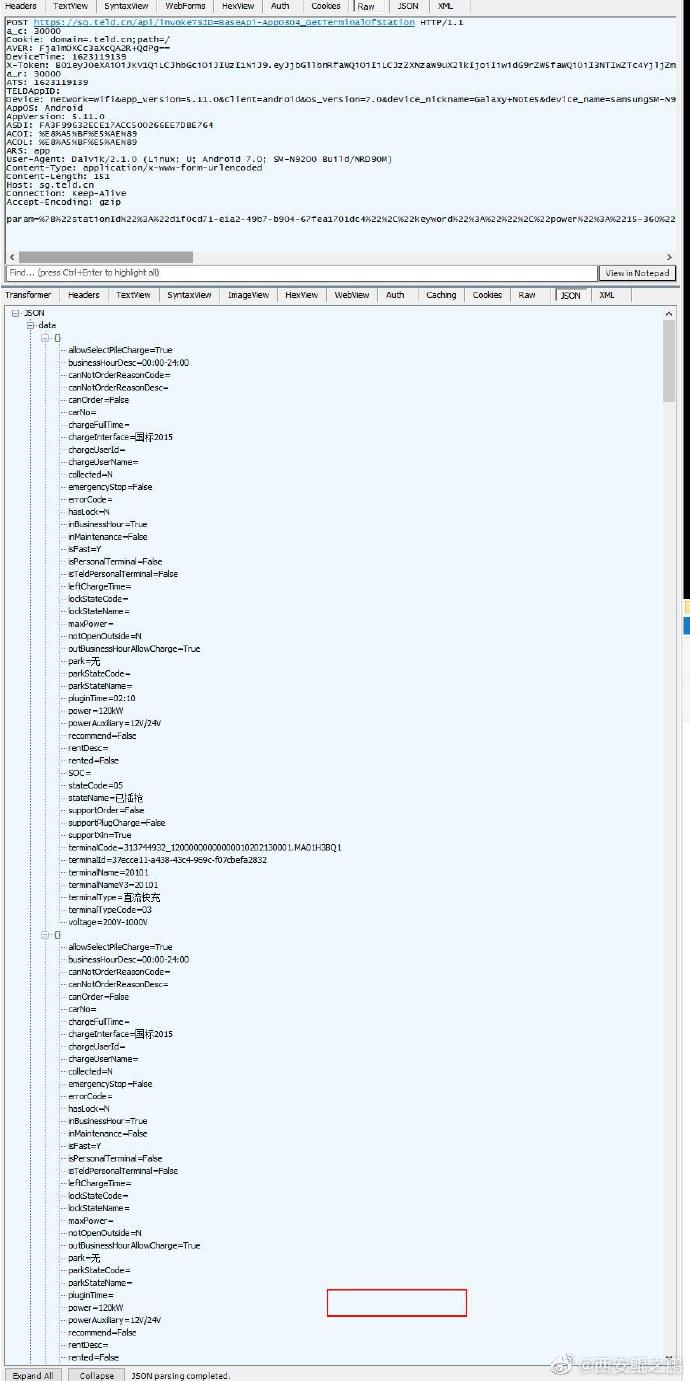
【经验分享】某特来电APP采集方案
我们分析的是V5.11.0版本,加了360的壳,用了ssl证书固定。
(1)经过ssl unpinning之后,Fiddler成功抓到包,如图1-3所示,分别对应“充电站搜索返回的列表”,“充电站详情”和“充电站的终端列表”。可以看到请求头中有很多陌生的参数,例如AVER,它是怎么构造出来的?
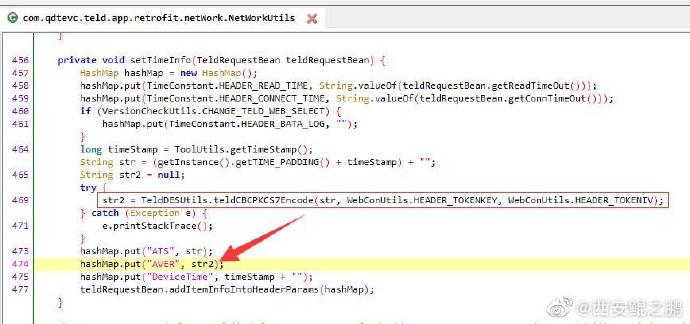
(2)脱壳,反编译找到了实现过程代码,如图4所示。可以看出AVER是通过对时间戳参数ATS,经过"DES/CBC/PKCS7Padding"加密而成。其它参数在代码中也都能找到实现过程。其中"X-Token"的产生过程比较复杂,后面再分享产生过程。发布时间:2021-06-08 12:10:34
-
【经验分享】com.google.gson.Gson的toJson()方法在插桩分析的时候太有用了,赞赞赞。
function toJson(javaObject) {
return Java.use("com.google.gson.Gson").$new().toJson(javaObject);
};
通过toJson(javaObject)可以将Java对象(数据结构)转换成JSON格式,非常方便。想想之前都是通过字符串拼接各个字段(熟悉)值,太费劲儿了。
关于com.google.gson.Gson的toJson()的更多示例可以看这篇文章:https://www.cnblogs.com/reboost/p/9521603.html发布时间:2021-06-04 10:57:34


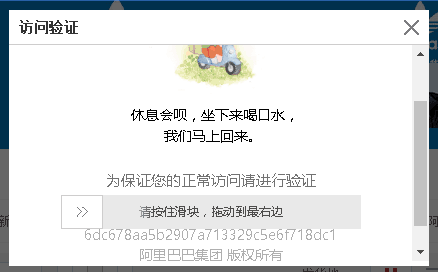
自2018年12月中旬之后,淘宝升级了反爬虫策略,淘宝Web版必须要登录之后才能使用搜索功能(直接搜索会被重定向到登录界面,登录之后才能看到搜索结果)。然而登录之后如果访问稍微频繁,就会出现滑块验证码(如下图所示),通过验证码之后(滑块验证码可以使用pyautogui自动处理),可以继续访问。
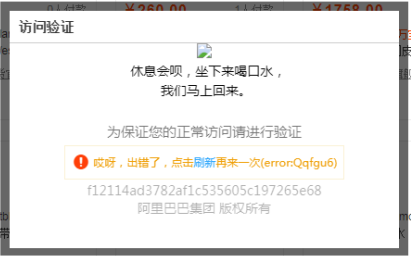
但如果持续访问频繁,就会出现一种无法处理的滑块验证码(如下图所示,持续提示“哎呀,出错了,点击刷新再来一次”),拖动之后会提示“”。由于这种机制的存在,导致采集效率低,一个淘宝账号每日仅能采集到5w条左右的商品,并且稳定性较差。
鲲之鹏的技术人员通过对比发现,手机淘宝APP版本并没有这种限制,不需要登录即可持续搜索,并且一个关键词能够看到的搜索结果条数也是4400条(和Web版一致)。但是淘宝APP同样有严密的防护策略,常规的抓包手段无法拦截到APP和服务端的交互数据,而且APK也做了防护,反编译后只能看到有限的代码。
通过技术人员的攻关,终于实现了突破,目前已可以有效拦截到手机淘宝APP的应答数据,能够拿到搜索结果返回的完整JSON数据,从而可以提取到和淘宝Web版一样的信息(例如 item_id, title, price, location, sold, commentCount, category, isB2c等等)。
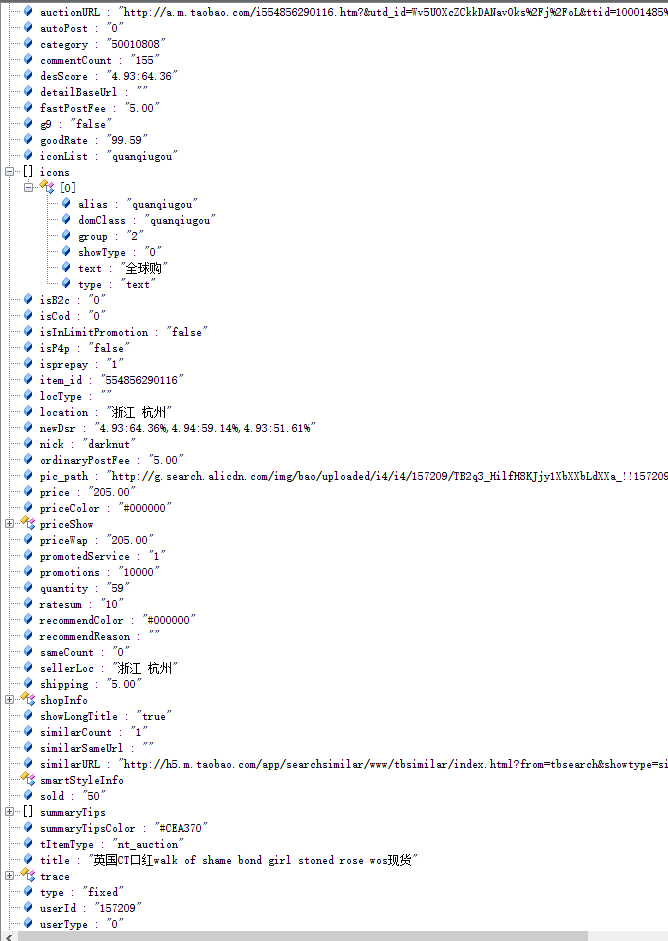
如下所示,为截取的一个手机淘宝APP搜索返回的一个商品的JSON示例数据。
完整的采集过程分为两步:
(1)通过adb模拟操作手机淘宝APP执行搜索和上滑翻页操作。
(2)拦截手机淘宝APP的应答数据,从中提取想要的信息。
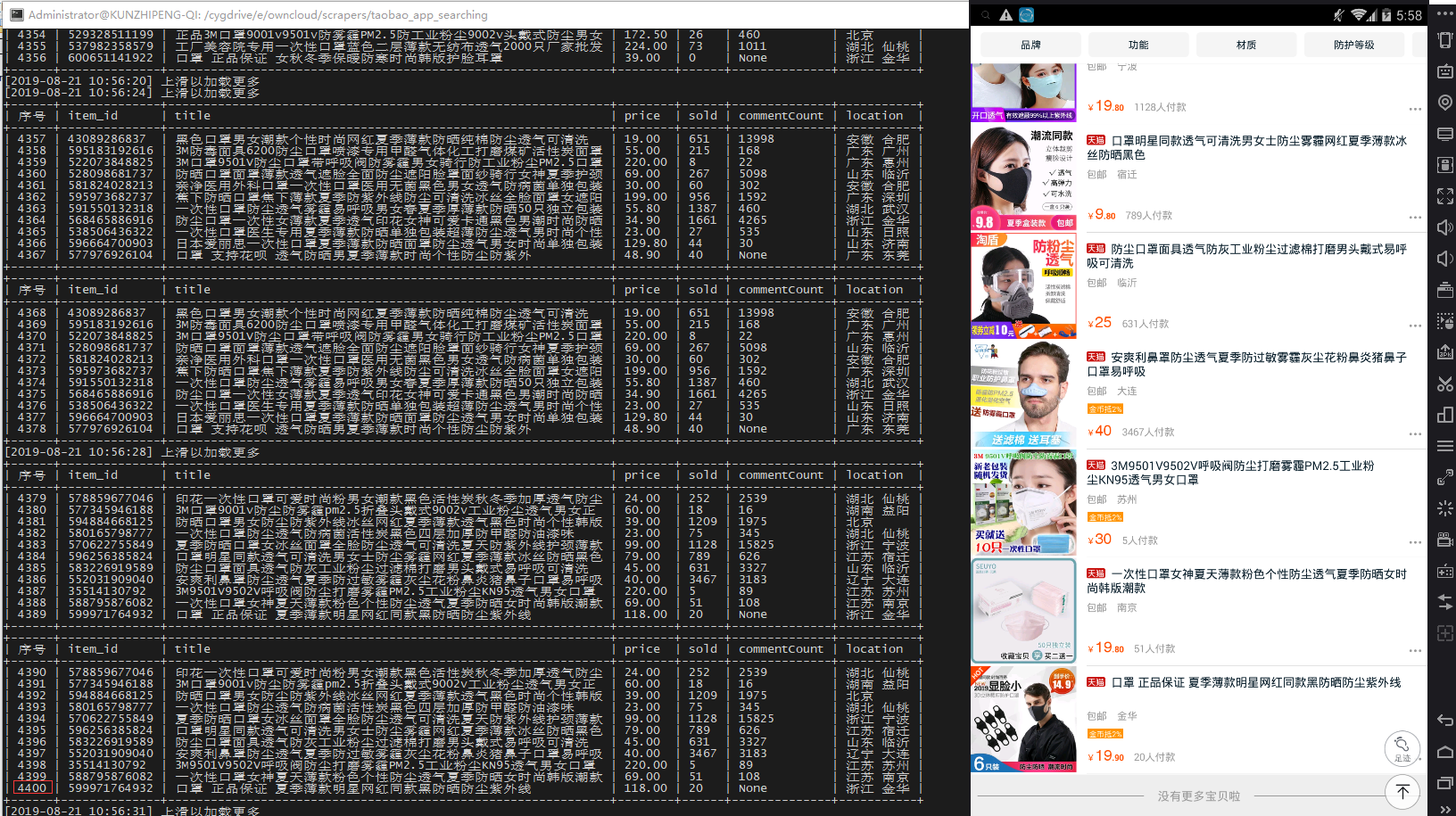
如下图所示,为采集过程的一个截图(左侧是实时抓取到的数据,右侧是安卓模拟器窗口):
这是一个抓取过程的演示视频,点击该链接 https://v.qq.com/x/page/i0923baptoh.html 到腾讯视频观看。
也可以点击该链接从本站直接播放:http://www.site-digger.com/uploads/videos/taobao_phone_app_keyword_searching_201908.mp4
再附上一个完整的手机淘宝APP关键词搜索返回的JSON数据:taobao_app_searching_sample.json
该方案有以下优点:
(1)无需淘宝账号登录,节省淘宝账号购买开支,不担心被封号;
(2)稳定可靠,采用淘宝手机APP数据源,不会轻易改版;
(2) 采集速度快,实测单台设备(可以采用模拟器,也可以采用真机),日均搜索采集量约20-30万条商品;
(3)IP限制弱;
如果你有类似的电商类数据采集分析需求,请和我们的客服人员联系。
