更多>>关于我们
 西安鲲之鹏网络信息技术有限公司从2010年开始专注于Web(网站)数据抓取领域。致力于为广大中国客户提供准确、快捷的数据采集相关服务。我们采用分布式系统架构,日采集网页数千万。我们拥有海量稳定高匿HTTP代理IP地址池,可以有效获取互联网任何公开可见信息。
西安鲲之鹏网络信息技术有限公司从2010年开始专注于Web(网站)数据抓取领域。致力于为广大中国客户提供准确、快捷的数据采集相关服务。我们采用分布式系统架构,日采集网页数千万。我们拥有海量稳定高匿HTTP代理IP地址池,可以有效获取互联网任何公开可见信息。
 您只需告诉我们您想抓取的网站是什么,您感兴趣的字段有哪些,你需要的数据是哪种格式,我们将为您做所有的工作,最后把数据(或程序)交付给你。
您只需告诉我们您想抓取的网站是什么,您感兴趣的字段有哪些,你需要的数据是哪种格式,我们将为您做所有的工作,最后把数据(或程序)交付给你。
 数据的格式可以是CSV、JSON、XML、ACCESS、SQLITE、MSSQL、MYSQL等等。
数据的格式可以是CSV、JSON、XML、ACCESS、SQLITE、MSSQL、MYSQL等等。
更多>>技术文章
更多>>官方微博
-
【经验分享】未解锁BL的手机进9008模式(Mi6X为例)
对于未解锁BL的手机,需要拆机,通过短接特定触点的方式进入9008模式。
以小米Mi6X为例:
第一步,拧掉充电口旁边的两颗螺丝。
第二步,扣开后盖,可能不太好扣,可以借助美工刀在边缘撬一下。拧掉保护条上的3个螺丝。
第三步,拔掉电池排线。看图,记着两个短接触点的位置。
第四步,用镊子短接两个触点,同时插入TypeC线,2秒左右设备管理器"端口COM"里会出现9008接口,此时松开镊子。发布时间:2024-11-27 10:13:20
-
【经验分享】已解锁BL的手机进9008模式
高通9008模式全称"Qualcomm HS-USB QDLoader 9008",它相对于recovery、fastboot和Android系统是独立的。即深刷模式,也叫EDL,号称"救砖神奇"。
对于已解锁BL的手机,进入9008相对比较简单,以小米Mi6X为例:
1. 先确定手机是否解锁BL了。已解锁BL的手机,刚开机的时候会有"Unlocked"字样,如附图1所示。
2. 长按“音量减键 + 开机键”进入fastboot。
3. 执行fastboot oem edl,即可进入9008模式,进入成功后设备管理器COM端口里可以看到"Qualcomm HS-USB QDLoader 9008"。如附图2、3所示。发布时间:2024-11-26 12:53:03
-
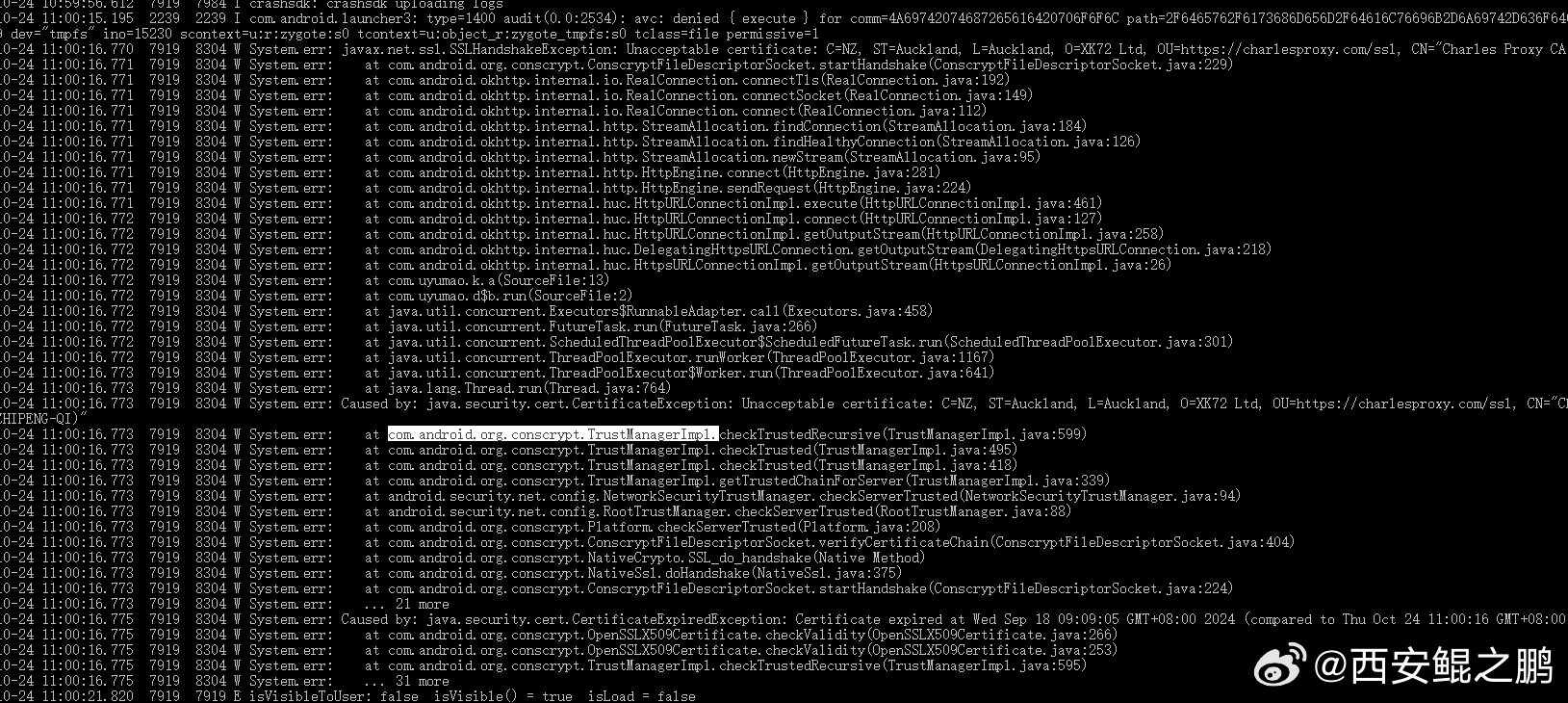
【经验分享】com.android.org.conscrypt.TrustManagerImpl证书固定检测绕过示例
某APP使用通用的sslunpinning脚本后仍然抓不到包:
(1)分析logcat日志,发现com.android.org.conscrypt.TrustManagerImpl类相关代码抛出java.security.cert.CertificateException异常,如图1所示。
(2)hook 类com.android.org.conscrypt.TrustManagerImpl的checkTrusted和checkServerTrusted方法,返回空列表,成功抓到包。
日志线索寻找关键词:CertificateException、CertificateExpiredExceptio、SSLHandshakeException发布时间:2024-10-24 15:36:45
-
【经验分享】如何获取安卓手机上已安装APP的安装包(.apk)文件?
1. 先查看已安装APP列表,确定对应APP的包名。
adb shell pm list packages
2. 假设包名为org.gushiwen.gushiwen。再根据包名查看APP的详细信息:
adb shell dumpsys package org.gushiwen.gushiwen
返回信息中的path属性,以base.apk结尾的,即就是这个APP的安装文件,如附图1所示。另外返回的信息中还有当前APP的版本(versionName属性),如附图2所示。
3. pull下来这个文件,就可以在其它设备上安装了。发布时间:2024-10-22 11:27:51
-
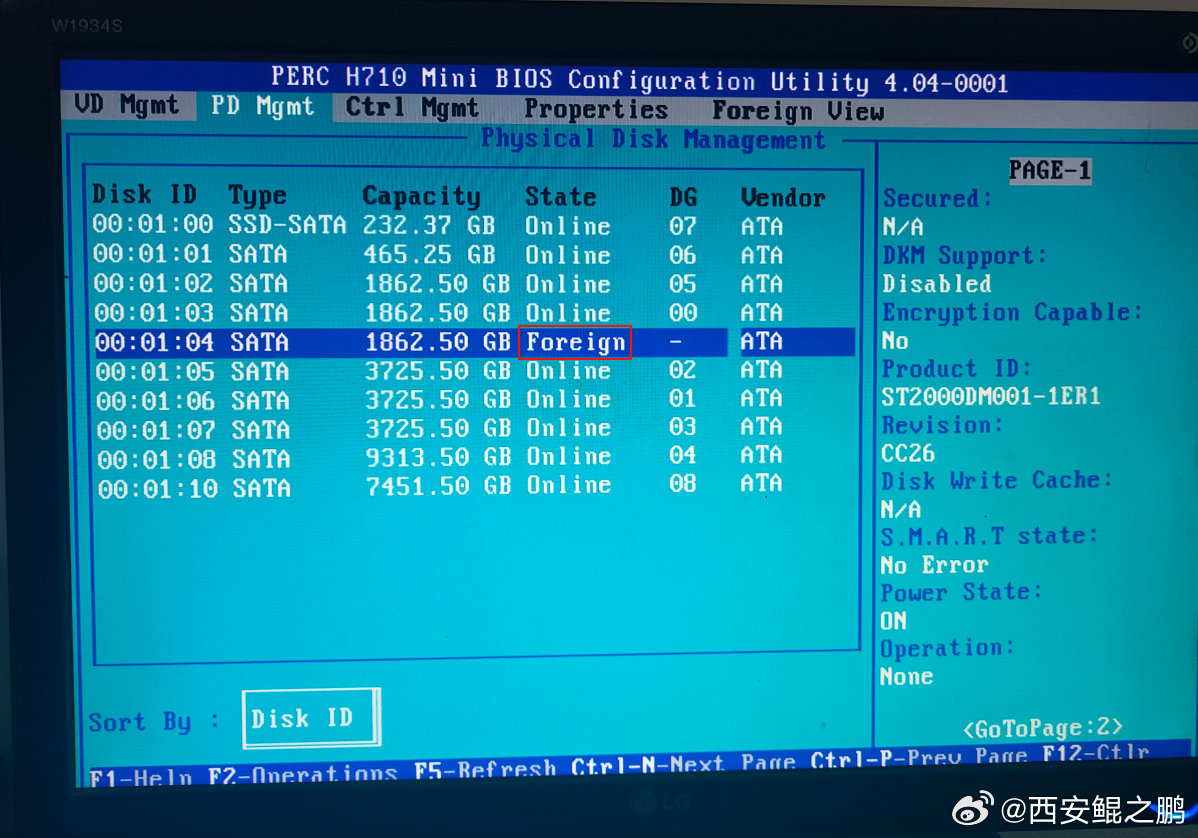
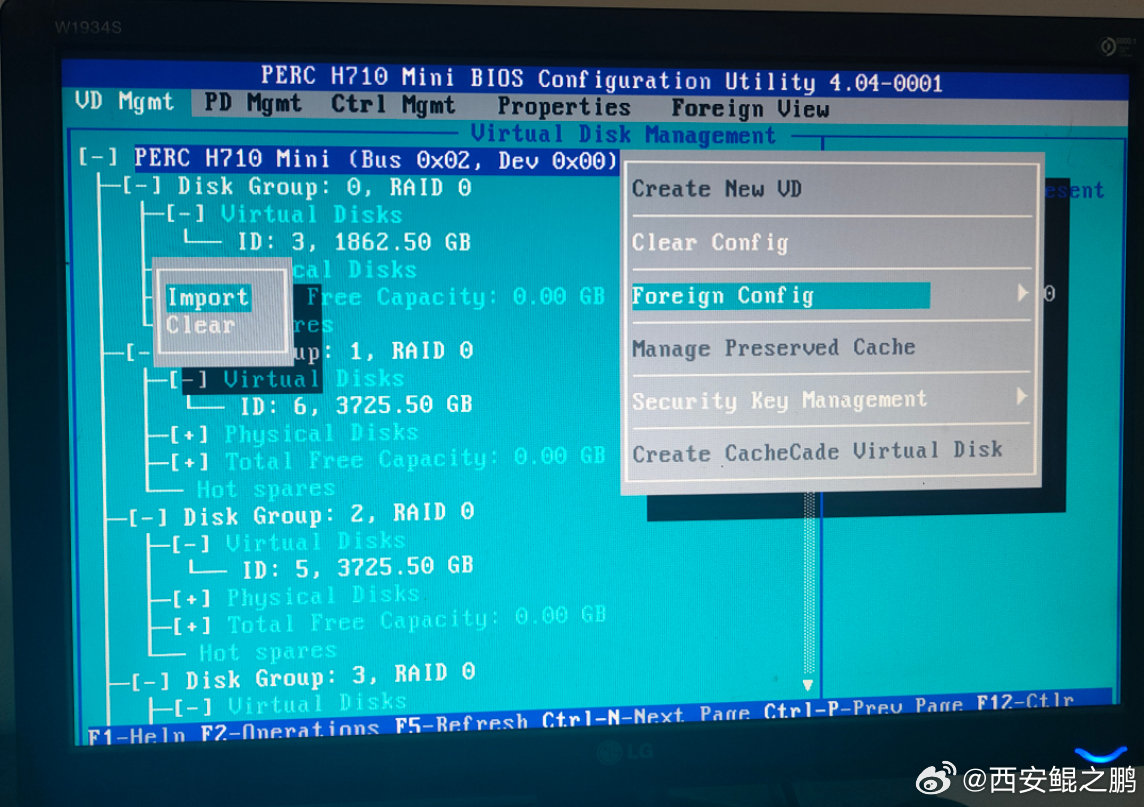
【经验分享】Dell R720意外断电重启之后丢失硬盘(硬盘状态变为Foreign)问题解决?
本来有10块盘,启动的时候显示只有9块Virtual Disk。“Ctrl + R”进入RAID设置,在“VD Mgmt”标签页下也只看到了9块Virtual Disk。在“PD Mgmt”标签页下看到是有10块物理盘,不过第5块状态变成“Foreign”了(如附图1所示)。
解决方法:在“VD Mgmt”标签页下,焦点切换到"PERC H710 Mini"上按F2,然后"Foreign Config",再然后"Import",操作完成(要等待几秒)之后就能看到全部盘了,如图2所示。
PS:用Ctrl + N快捷键切换菜单标签。发布时间:2024-10-18 16:35:44
-
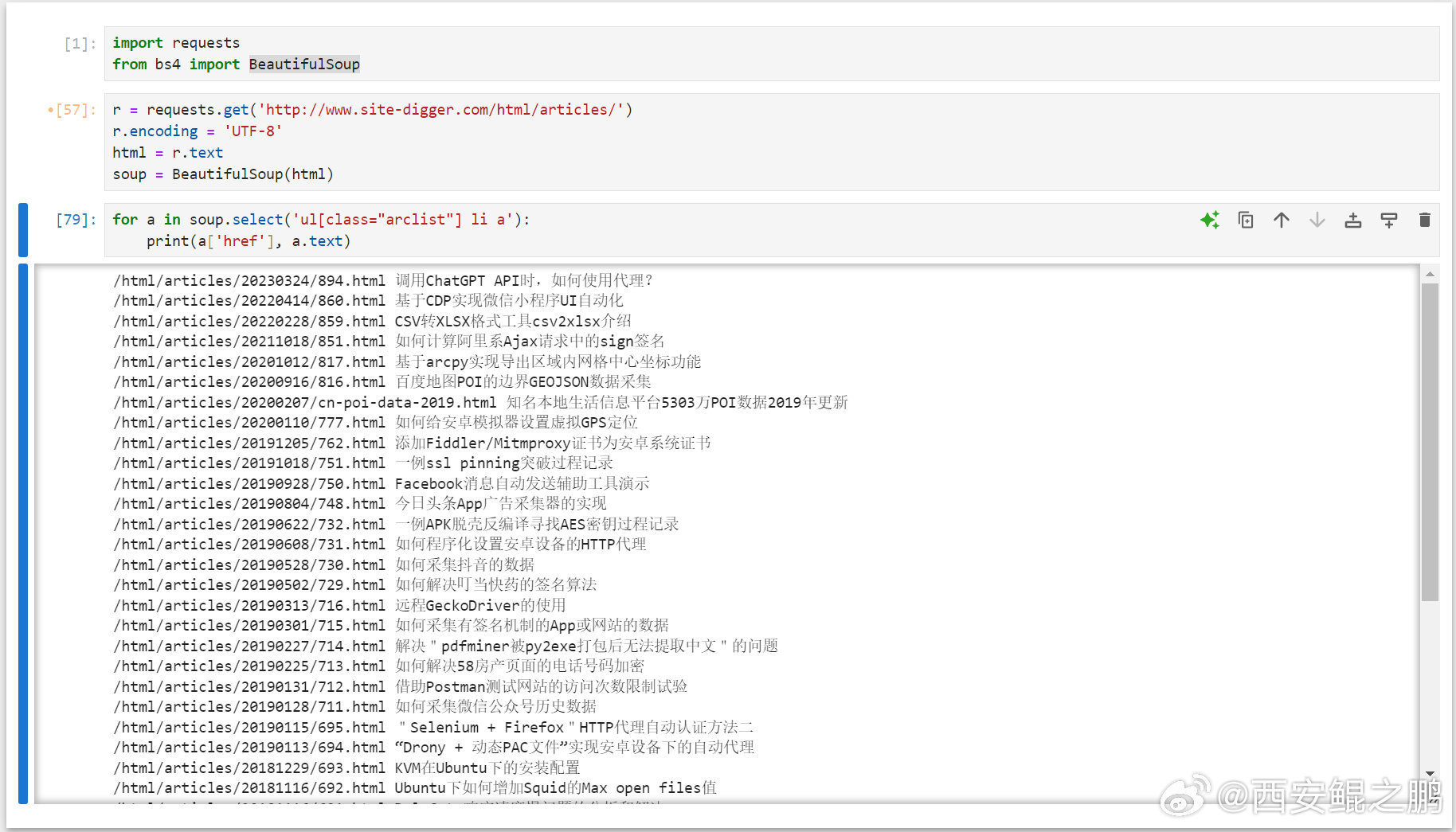
【经验分享】一个游戏闯关模式学习CSS Selector的网站"CSS Diner":https://flukeout.github.io/。
Python使用BeautifulSoup实现CSS Selector解析HTML文档的示例:
import requests
from bs4 import BeautifulSoup
r = requests.get('http://www.site-digger.com/html/articles/')
r.encoding = 'UTF-8'
html = r.text
soup = BeautifulSoup(html)
for a in soup.select('ul[class="arclist"] li a'):
print(a['href'], a.text)发布时间:2024-09-02 19:43:03
-
【经验分享】qemu-system-x86运行tiny11
(1) 安装qemu-system-x86,安装完成后无需重启。
sudo apt-get update
sudo apt-get install qemu qemu-utils qemu-system-x86
(2) 创建硬盘。
qemu-img create -f qcow2 tiny11.img 50G
(3) 创建虚拟机。
sudo qemu-system-x86_64 --enable-kvm -m 2G -smp 4 -boot order=dc -hda /home/qi/kvm/tiny11-1/tiny11.img -cdrom /home/qi/kvm/tiny11_23H2_x64.iso -vnc :1
(4) vnc连接 "服务器ip:5901",完成系统安装过程。设置vnc密码的方法:https://qemu-project.gitlab.io/qemu/system/vnc-security.html#with-passwords。
(5) 映射主机端口给虚拟机,使用-redir参数。如下示例,将主机的TCP/UDP4001端口映射到虚拟机的4000端口。
-redir tcp:4001::4000 -redir udp:4001::4000发布时间:2024-08-10 12:13:46
-
【经验分享】Playwright过geo.captcha-delivery.com检测
page.add_init_script('''Object.defineProperties(navigator, {webdriver:{get:()=>undefined}}); delete navigator.__proto__.webdriver;''') 发布时间:2024-07-31 10:41:18
-
【经验分享】scrcpy在网络质量欠佳环境下可以通过降低码率来提高流畅度
e.g.
scrcpy --bit-rate 1M --max-fps 5
注意:在新版本中--bit-rate参数更名为--video-bit-rate 发布时间:2024-07-03 10:11:54
-
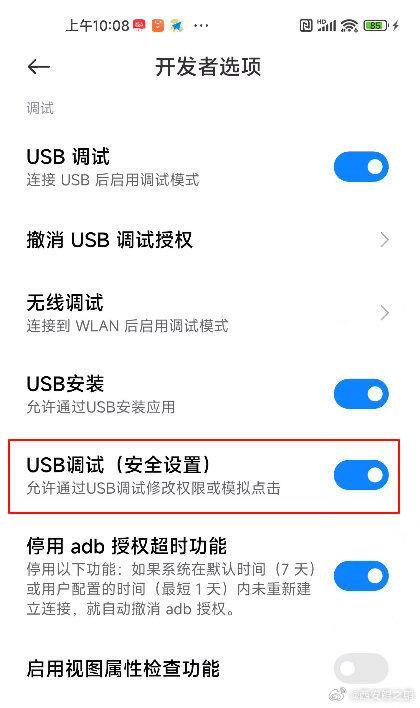
【经验分享】scrcpy在小米手机上鼠标不起作用问题的解决
在“开发者选项”中需要打开"USB调试(安全设置) - 允许通过USB调试修改权限或模拟点击"。要打开这个选项,手机需要先登录小米账号,另外手机必须要插有SIM卡。 发布时间:2024-07-03 10:09:29











-
西安鲲之鹏
发布时间:2020-06-14 19:04:23
【经验分享】毒(得物)APP签名算法解决
(1)HTTP请求做了"手脚"无法直接抓到包。
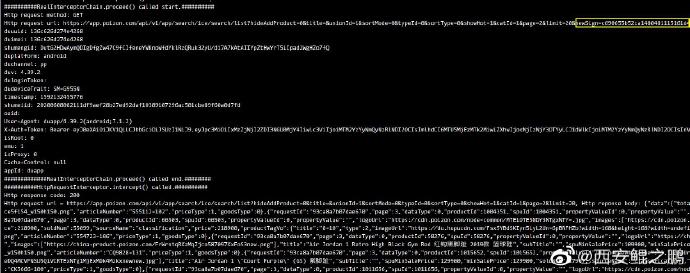
(2)分析代码后发现可以通过HOOK "com.shizhuang.duapp.common.helper.net.interceptor.HttpRequestInterceptor.intercept()"调用或者"okhttp3.internal.http.RealInterceptorChain.proceed()"调用拿到HTTP请求和应答数据(如图1所示)。
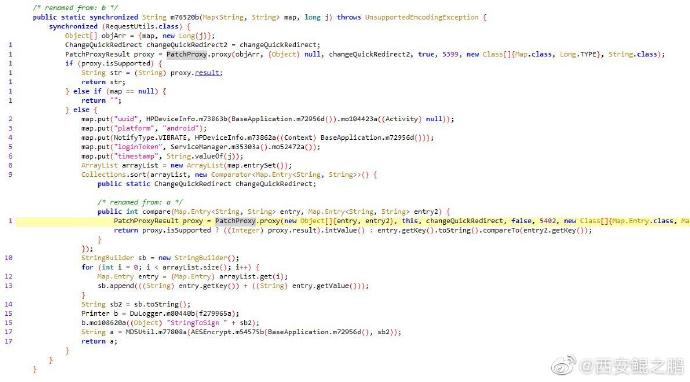
(3)分析发现不关是GET请求,还是POST请求,都有一个签名参数newSign。签名算法位于com.shizhuang.duapp.common.utils.RequestUtils中,签名算法原理是对QueryString或Request Body中的参数以及一些特定的Headers排序后进行加密(具体加密算法是在native层实现的,位于libJNIEncrypt.so中),然后对加密结果进行MD5计算(如图2)。
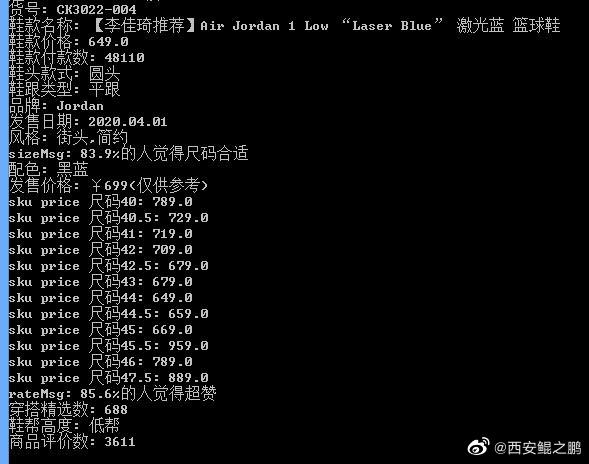
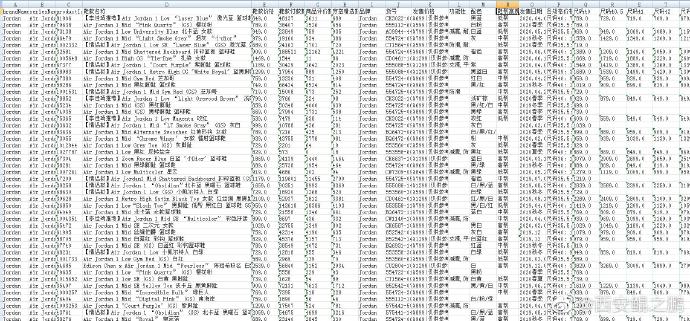
(4)分析出来原理后,思路就清晰了:自己构造HTTP请求,通过HOOK + RPC形式直接调用RequestUtils中的签名算法,产生有效的签名值,这样就能直接拿到接口返回的数据。如图3、4所示为最终采集到的数据。 -
西安鲲之鹏
发布时间:2020-06-04 10:20:59
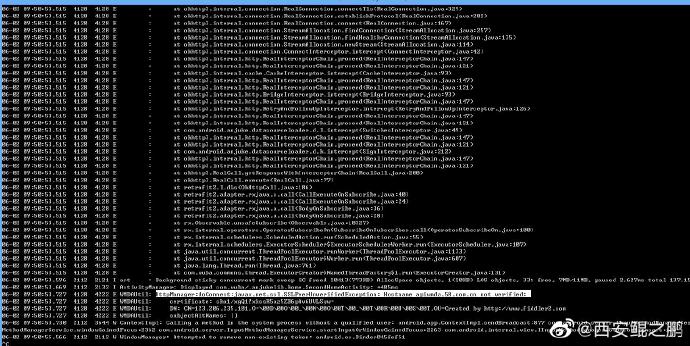
【经验分享】58同城APP证书固定机制绕过(ssl unpinning)方法
1. 直接抓包,APP提示网络错误(图1),logcat显示有okhtt3 connectTls相关函数异常(图2)。
2.反编译APK,根据异常提示定位到证书锁定相关代码。
3. 使用Frida Hook绕过相关证书验证代码。具体frida脚本如下:
Java.perform(function() {
console.log("##### com.wuba SSL UNPINNING #####");
var OkHostnameVerifier = Java.use('okhttp3.internal.tls.OkHostnameVerifier');
OkHostnameVerifier.verify.overload('java.lang.String', 'java.security.cert.X509Certificate').implementation = function(arg1, arg2){
console.log("OkHostnameVerifier.verify('java.lang.String', 'java.security.cert.X509Certificate') called.");
console.log(arg1);
console.log(arg2);
return true;
}
OkHostnameVerifier.verify.overload('java.lang.String', 'javax.net.ssl.SSLSession').implementation = function(arg1, arg2){
console.log("OkHostnameVerifier.verify('java.lang.String', 'javax.net.ssl.SSLSession') called.");
console.log(arg1);
console.log(arg2);
return true;
}
var CertificatePinner = Java.use('okhttp3.CertificatePinner');
CertificatePinner.check.overload('java.lang.String', 'java.util.List').implementation = function (arg1, arg2) {
console.log('CertificatePinner.check() called. ');
console.log(arg1);
console.log(arg2);
}
var OpenSSLSocketImpl = Java.use('com.android.org.conscrypt.OpenSSLSocketImpl');
OpenSSLSocketImpl.verifyCertificateChain.implementation = function (arg1, arg2) {
console.log('OpenSSLSocketImpl.verifyCertificateChain() called.');
console.log(arg1);
console.log(arg2);
}
}};
'''
4. 成功抓到相关HTTPS数据包(图3)。 -
西安鲲之鹏
发布时间:2020-05-26 17:33:42
【经验分享】VMware Workstation开机免登录自启动设置方法
近日某拨号服务器出现故障,不定期会自动重启。每次重启之后都要手动去启动VMware虚拟机,非常麻烦。如何实现开机自启动指定的VMware虚拟机呢?
(1)通过"vmrun.exe start 虚拟机vmx文件路径"命令可以启动指定的虚拟机。
如果有多个虚拟机可以创建一个如下批处理:
"C:\Program Files (x86)\VMware\VMware Workstation\vmrun.exe" start "E:\鲲之鹏\ubuntu16.04-adsl-proxies-server-1\Ubuntu 64 位.vmx"
"C:\Program Files (x86)\VMware\VMware Workstation\vmrun.exe" start "E:\鲲之鹏\ubuntu16.04-adsl-proxies-server-2\Ubuntu 64 位.vmx"
"C:\Program Files (x86)\VMware\VMware Workstation\vmrun.exe" start "E:\鲲之鹏\ubuntu16.04-adsl-proxies-server-3\Ubuntu 64 位.vmx"
...
(2)将上述批处理文件添加到开机启动计划任务里。
* 触发器,新建触发器,开启任务选择“启动时"。
* 常规选项卡,安全选项选择“不管用户是否登录都要运行”。这一步很重要。
为什么不直接放到“启动文件夹”中,而要使用计划任务呢?
因为放到启动文件夹中必须要用户登录之后才能被执行。这样就达不到免登录自启动的效果了。 -
西安鲲之鹏
发布时间:2020-05-11 09:38:32
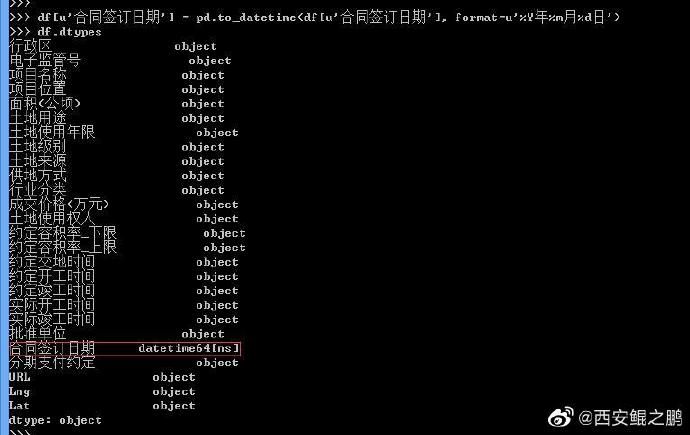
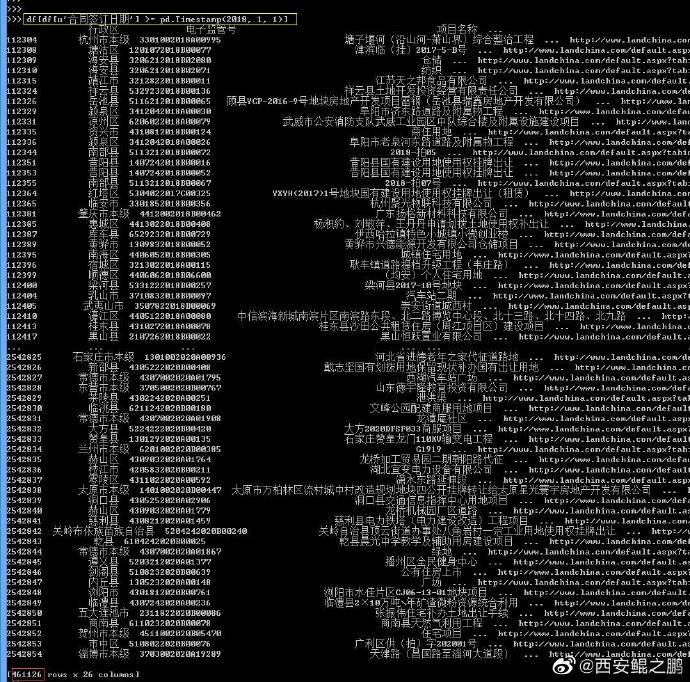
【经验分享】Pandas日期范围查询
目的:查询CSV中某列值大于某个日期的记录。
(1)使用Pandas的to_datetime()方法,将列类型从object转为datetime64。
df[u'合同签订日期'] = pd.to_datetime(df[u'合同签订日期'], format=u'%Y年%m月%d日')
注意要设置format参数,指定原始数据的时间日期格式。转换完成后可以查看dtypes属性确认,如附图1所示。参考:https://stackoverflow.com/questions/36848514/how-to-define-format-when-use-pandas-to-datetime
(2)查询日期大于2018年1月1日的记录。
df[df[u'合同签订日期'] >= pd.Timestamp(2018, 1, 1)]
结果如附图2所示,参考:https://stackoverflow.com/questions/36104500/pandas-filtering-and-comparing-dates -
西安鲲之鹏
发布时间:2020-05-08 21:05:47
【经验分享】Python的hash()函数产生hash碰撞的概率有这么高吗?
昨天同事"随手"给我发了两组他在项目中遇到的例子,很是受"惊吓",HashDict用了快10年了,竟然没注意到这个Bug。
Python 2.7.8.10 on Windows 64
例一:
hash(u'赤峰_1513781081_http://t.cn/A6Al6TDu)
901186270
hash(u'北京_1010215433_http://t.cn/A6Al6TDn)
901186270
例二:
hash('B033900G0Z')
80468932
hash('B021307H9T')
80468932
注意: Linux 64 下测试上述两组值并不相同,另外Linux下hash()产生的hash串长度要比Windows下长很多,产生hash碰撞的概率应该也会小很多。 -
西安鲲之鹏
发布时间:2020-04-15 10:53:11
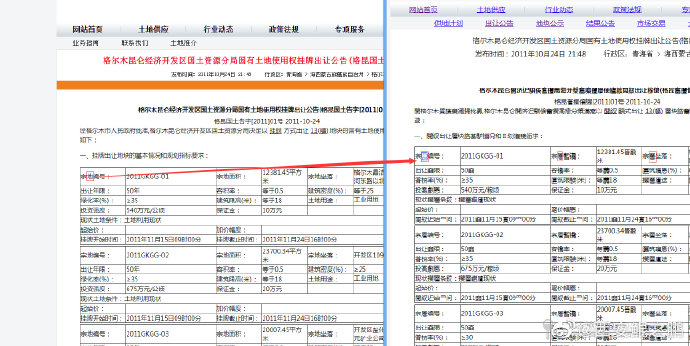
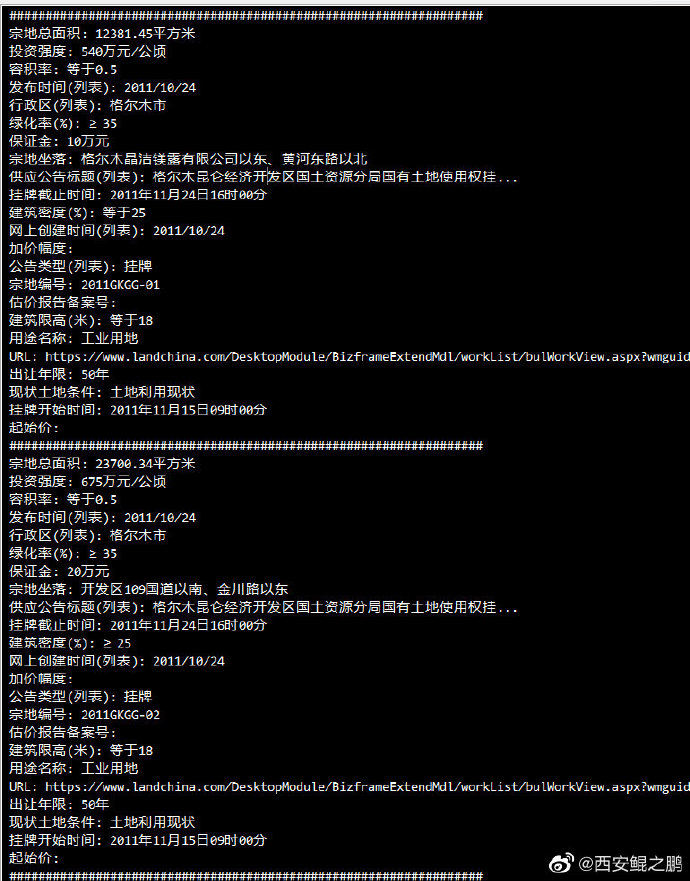
【经验分享】"土地市场网-土地供应-出让公告"网页字体混淆反采集的解决
(1)如附图1所示,下载的页面中有很多字符是乱码。左边是经过浏览器正确渲染的结果,右边是下载到的有乱码的数据。
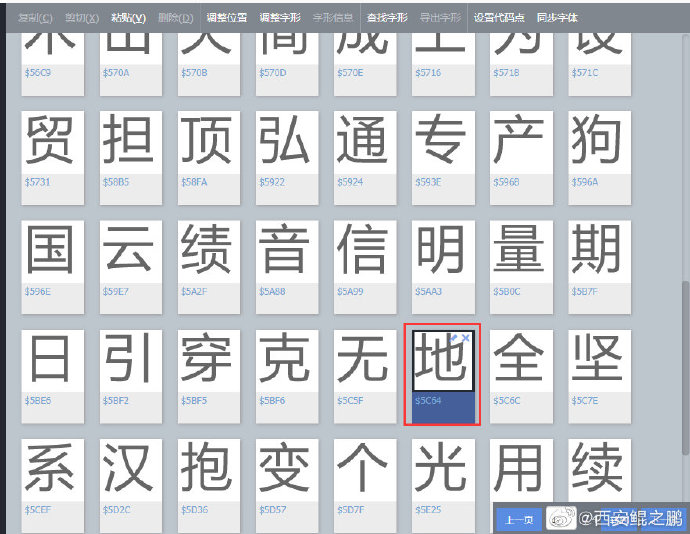
(2)经过分析发现,网站使用了自定义的字体文件:把常用的391个汉字做成了特殊字体,使用了自定义的unicode码。如附图2所示。这种字体混淆的反采集策略现在很常见了,之前曾在猫眼电影、汽车之家、58等网站都见到过。
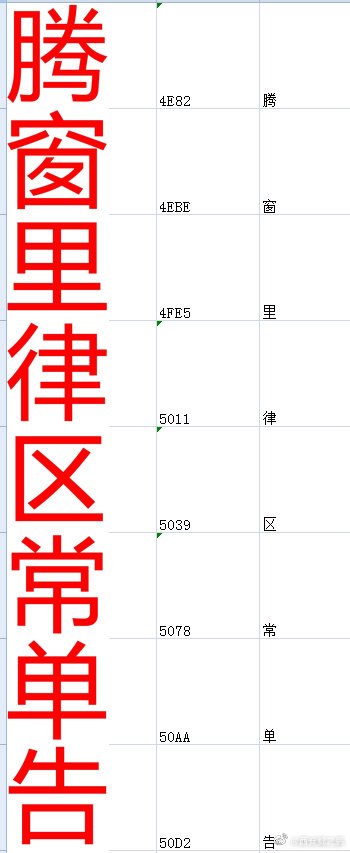
(3)经过深入分析发现,网站总共使用了10个自定义的字体文件(如图3所示),每个文件内的字符是一样的(都是那391个字符),但是相同的unicode码对应的字符是不一样的。如附图4所示,uni3075在3个字体文件中对应的字符分别是“悬”、“亲”和“田”。
(4)突破这种策略的思路很简单,就是建立一个“unicode码->字符"的映射表,然后将HTML中的这些乱码(unicode码)替换成明文即可。但是本例中有10 * 391 = 3910个字符,工作量太大了。
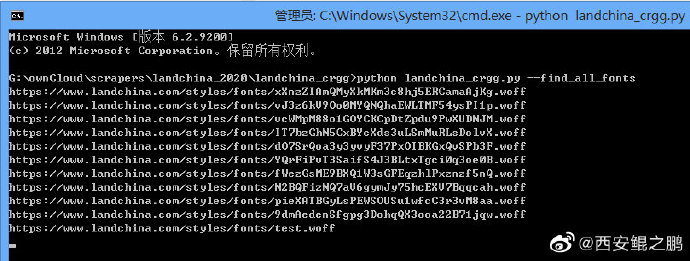
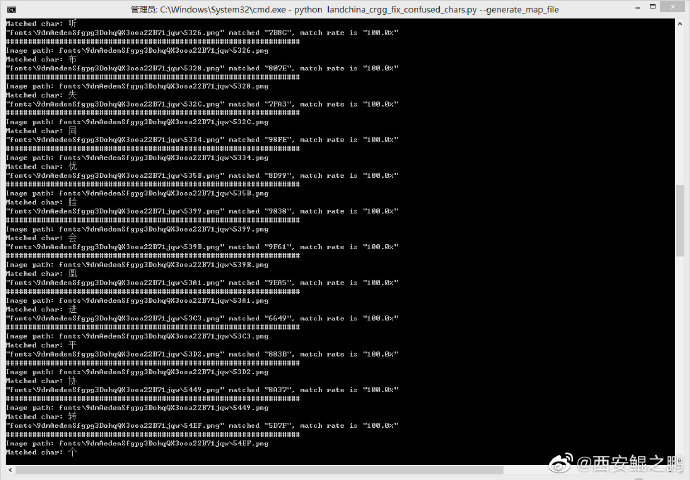
(5)于是想到一个“偷懒”的方法:由于每个文件内都是那391个字符,我只手动建立一个映射表,其余的通过图片匹配自动建立。
我把这个脚本放到了gist上“将字体文件内各字体导出图片存储,并建立一个Excel索引”(http://t.cn/A6wxdZxl)。
如附图5所示,是上述脚本输出的每个字符对应的图片。
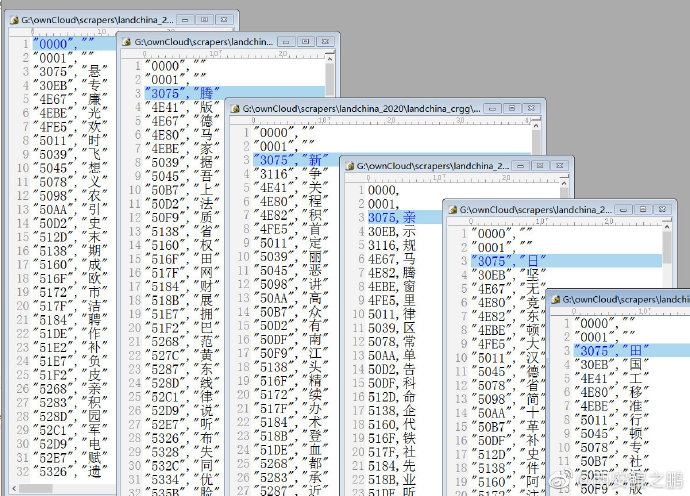
如附图6所示,这个Excel文件也是上述脚本生成的,然后人工填入每个图片对应的明文字符,这样就建立好了一个字体文件的字符映射表。把这个表当做特征库表。
(6)将其他9个字体文件中的图片也使用上述脚本导出,然后挨个和特征库对比(这里我直接通过像素值二维数组进行对比,将一致率最高的视为匹配),建立匹配关系,如图7所示。
最终生成其它10张字符映射表,如附图8所示。
(7)有了这10张完备的字体映射表,还原明文就so easy了,最终还原后的提取结果如附图9所示。 -
西安鲲之鹏
发布时间:2020-04-07 11:49:57
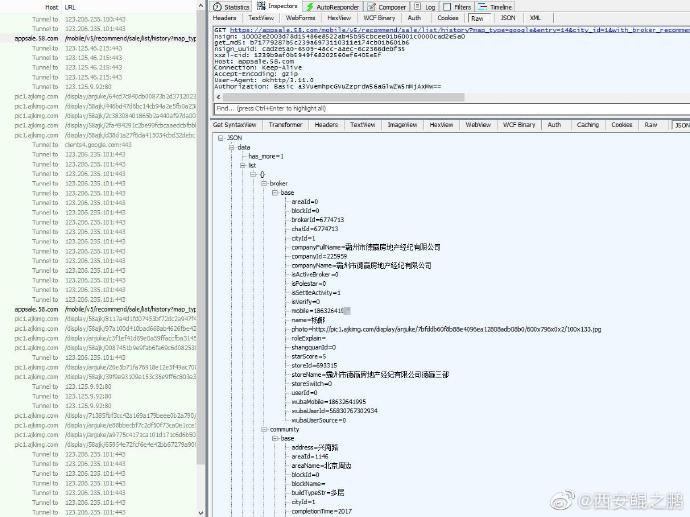
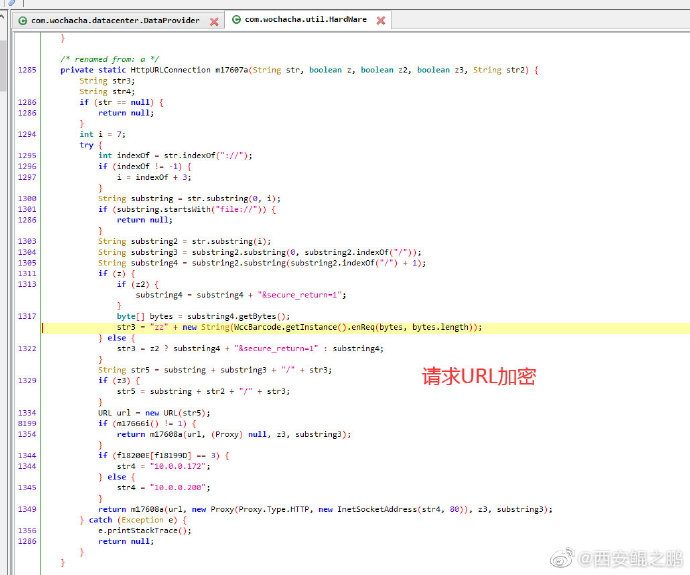
【经验分享】我查查APP防护机制分析
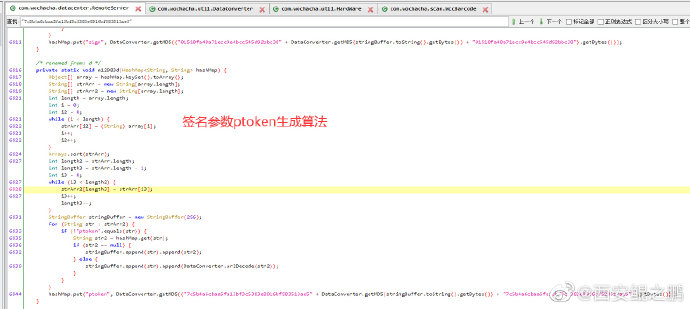
1. 最明显的是URL加密了,如附图1所示。
反编译后分析源码可知,URL加密过程如附图2所示。
主要通过WccBarcode.getInstance().enReq(bytes, bytes.length)实现。
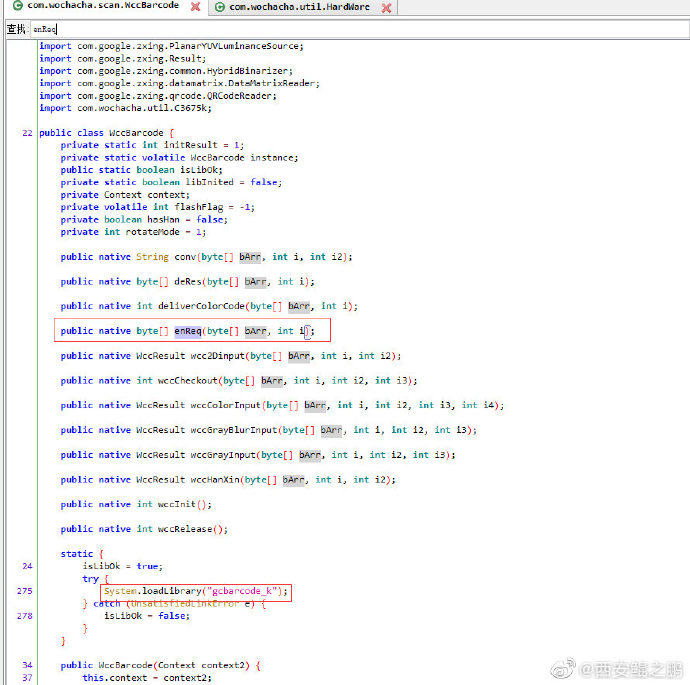
2. enReq()是一个native方法,具体实现在libgcbarcode_k.so中,如附图3所示。
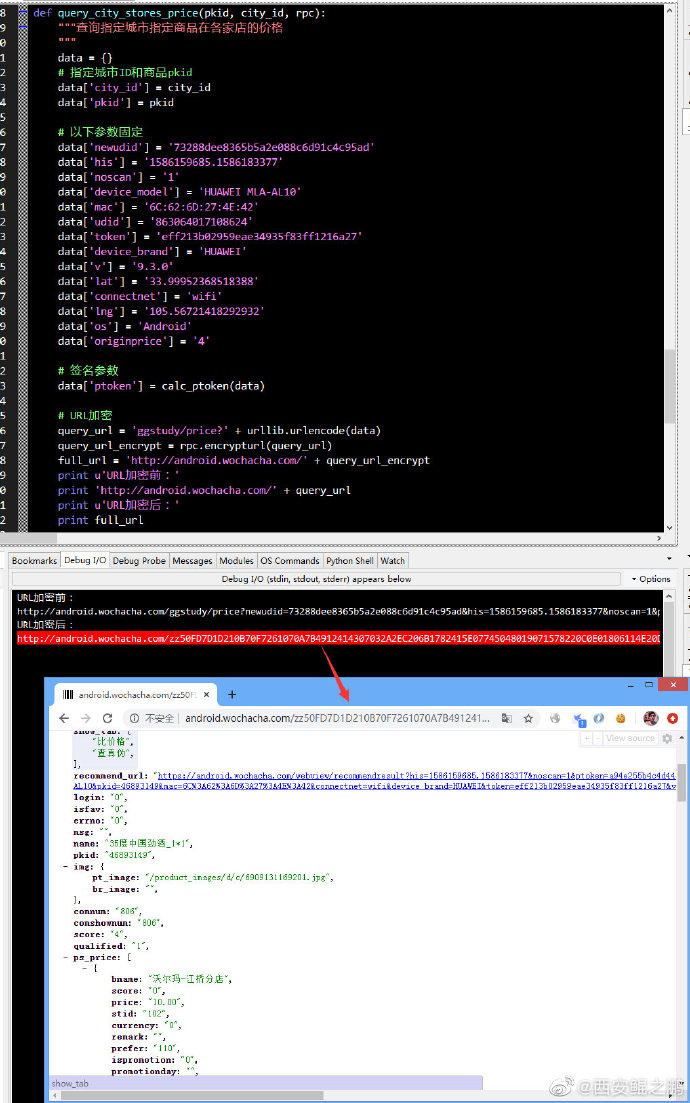
例如,原始URL:
/ggstudy/price?city_id=1&pkid=46893149&token=eff213b02959eae34935f83ff1216a27&mac=6C%3A62%3A6D%3A27%3A4E%3A42&his=1586159685.1586183377&newudid=73288dee8365b5a2e088c6d91c4c95ad&ptoken=a94e255b4c4d444a9c66a324160bb63b&noscan=1&connectnet=wifi&lng=105.56721418292932&os=Android&v=9.3.0&originprice=4&device_model=HUAWEI+MLA-AL10&device_brand=HUAWEI&udid=863064017108624&lat=33.99952368518388
经过加密后变成:
/zzE06D4C3D909AE1E6261070A7B491241430713222ECA16B97C2005E0CB490484AB8713F03F811CB0A04522B2BAC2126961E31190DA820061096034A0BDC410713BC623924CC90A3C69A01182D1890......
3. 上面有一个ptoken要特别注意,这其实是一个签名参数,具体的实现过程在com.wochacha.datacenter.es.d()方法中,如附图4所示。
思路是先将querystring的key按从大到小排序,然后拼接成一个串,计算MD5后,再前后拼接上一个常量串(加盐),再次计算MD5。
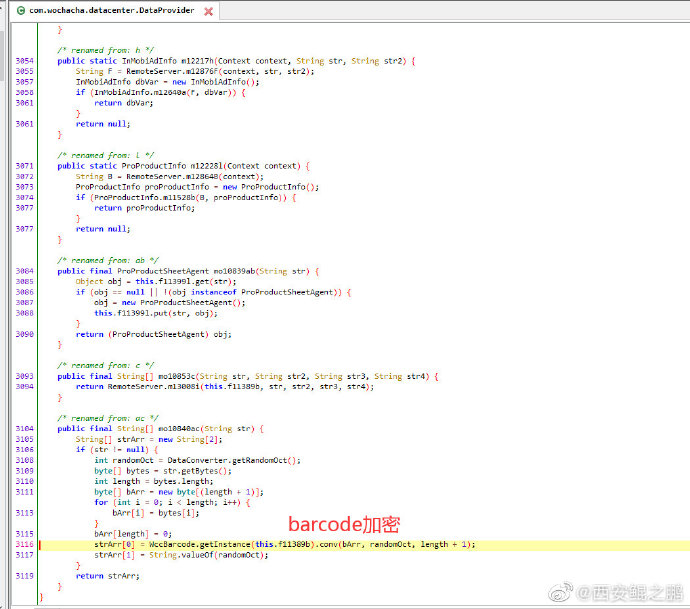
4. 另外,根据输入条码查询商品时,输入的barcode也被做了特殊处理。如图5所示。这里也调用了libgcbarcode_k.so中的native方法,conv()。
了解上述过程后,我们就能自己过程出有效的HTTP请求,拿到数据。对于so中的算法,直接还原有难度,可以通过Frida RPC间接调用。最终效果如附图6所示。 -
西安鲲之鹏
发布时间:2020-03-30 15:49:15
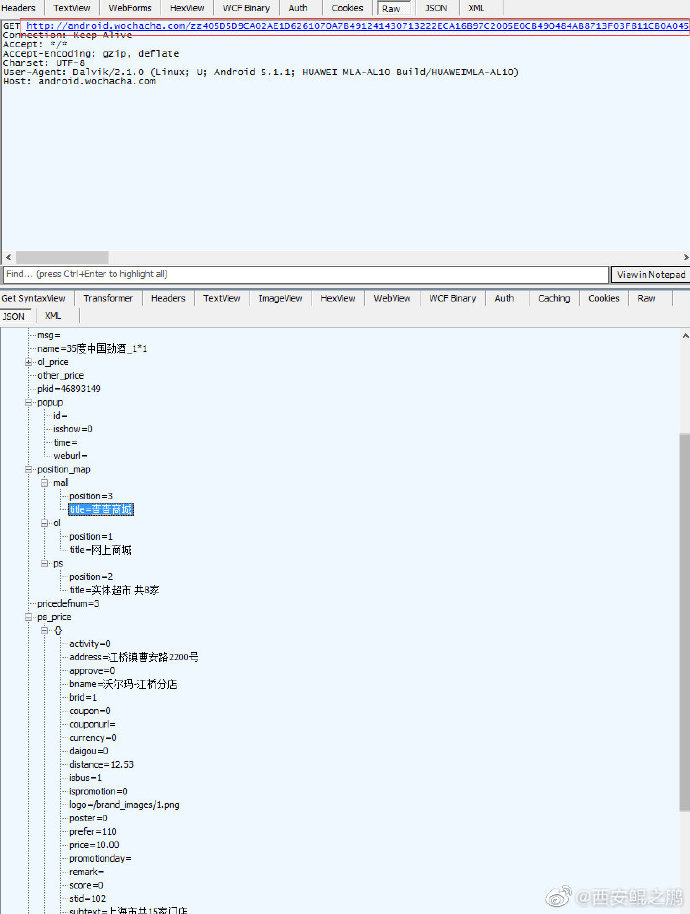
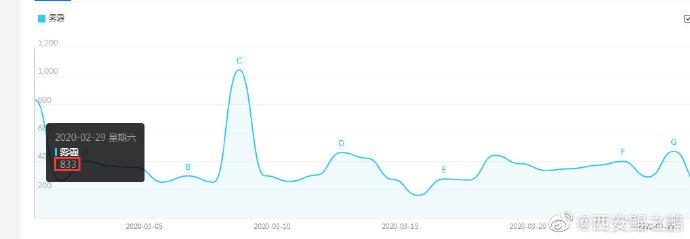
【经验分享】终于搞定了百度指数PC版(2020最新版)加密算法,不用再模拟浏览器采集了
之前一直是使用"phantomjs + js脚本"模拟操作,从UI上获取百度指数值。
今天有客户让评估新的需求,之前模拟浏览器的方式不太适合了,决定试着分析下它的解密算法。
运气不错,没花多大功夫搞定了,以后可以直接通过HTTP交互采集了。
简单介绍下步骤:
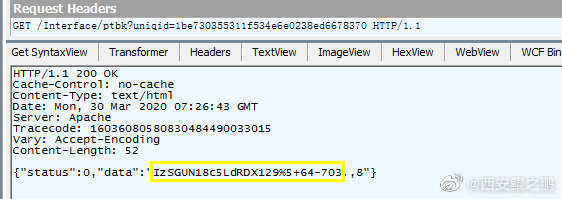
1. 通过/api/SearchApi/index接口获取到密文数据,以及uniqid参数。如附图1所示。
2. 通过/Interface/ptbk接口获取解密用的密码,这里要用的上一步返回的uniqid参数。如附图2所示。
3. 调用解密算法decrypt(password, data),根据2中获取到的password,和1中获取到的密文data,成功解出明文,如附图3所示。
解密算法这里就不公布了,感兴趣的可以在js里找一找。
解出的明文和浏览器显示的结果对比一下,如附图4所示,吻合。 -
西安鲲之鹏
发布时间:2020-03-29 16:29:58
【经验分享】记录使用"静态分析+动态插桩"还原“永辉超市某版本APP的HTTP签名算法”过程
背景:永辉超市某版本APP的HTTP请求使用了签名参数保护机制,下面是分析该签名算法的过程:
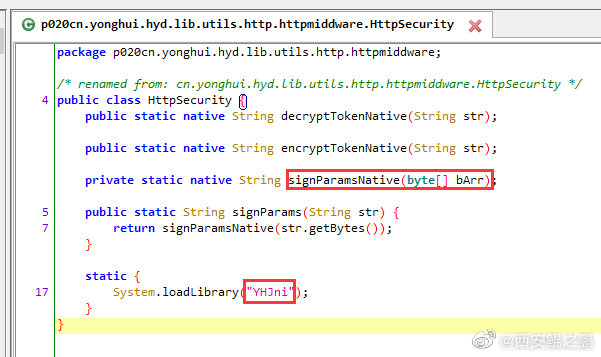
1. Jadx反编译APK,通过Java代码可以定位到加密函数位于cn.yonghui.hyd.lib.utils.http.httpmiddware.HttpSecurity类的signParamsNative()方法。如附图1所示。
2. signParamsNative()是一个native方法,实现过程在libYHJni.so中。根据经验,直接还原算法可能有难度。通过Frida对HttpSecurity.signParams()动态插桩,插装代码如下:
Java.perform(function() {
var HttpSecurity = Java.use('cn.yonghui.hyd.lib.utils.http.httpmiddware.HttpSecurity');
HttpSecurity.signParams.implementation = function(arg1){
var md5 = this.signParams(arg1);
console.log("##### In HttpSecurity.signParams(): #####");
console.log('Input param:');
console.log(arg1)
console.log('Sign result:');
console.log(md5);
console.log("###########################################");
return md5;
}
}
成功拦截到某次函数调用,输出如下:
##### In HttpSecurity.signParams(): #####
Input param:
channelofficialdeviceidc7f00557-f9e8-4c59-8207-1da0909e9130distinctId66c626d274e42556isfirstopen0lat39.008006lng103.572384platformAndroidtimestamp1585469368166v5.28.0.10
Sign result:
baec2be68929009758ed7de29c331fdf
###########################################
3. 如上输出。“channelofficialdeviceidc7f00557-f9e8-4c59-8207-1da0909e9130distinctId66c626d274e42556isfirstopen0lat39.008006lng103.572384platformAndroidtimestamp1585469368166v5.28.0.10”参数串,经过某个算法之后得到一个的结果是一个32位的串"baec2be68929009758ed7de29c331fdf"。试了一下直接md5,结果不对。猜测可能是加salt了。
4. 用IDA静态分析libYHJni.so,很容易找到Java_cn_yonghui_hyd_lib_utils_http_httpmiddware_HttpSecurity_signParamsNative()的实现,按F5将汇编代码转换为C语言语法。如附图2所示。从代码可以看出,计算输入串MD5值之前,先在前面加上了"YONGHUI601933",也就是md5("YONGHUI601933" + 输入串)。
5. 知道算法了,我们来验证一下:
>>>import hashlib
>>>param = 'channelofficialdeviceidc7f00557-f9e8-4c59-8207-1da0909e9130distinctId66c626d274e42556isfirstopen0lat39.008006lng103.572384platformAndroidtimestamp1585469368166v5.28.0.10'
>>>hashlib.md5('YONGHUI601933' + param).hexdigest()
'baec2be68929009758ed7de29c331fdf'
结果吻合。 -
西安鲲之鹏
发布时间:2020-03-27 23:09:52
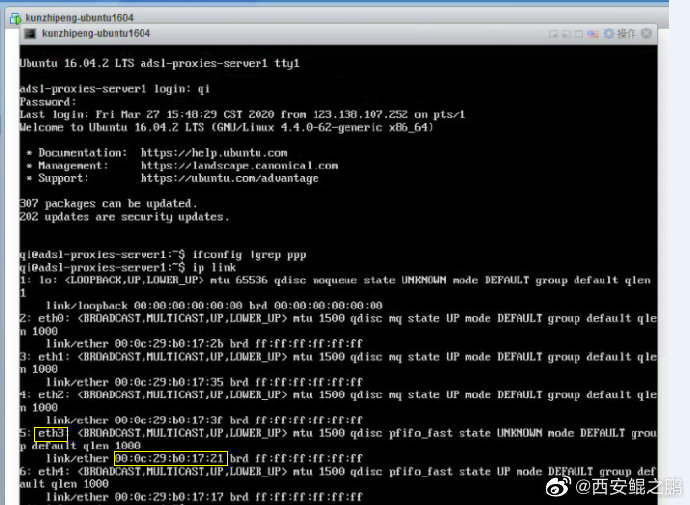
【经验分享】
背景:
ESXi搭建的Ubuntu16.04虚拟机,添加了5块虚拟网卡,不同的网口桥接的不同的Bas。
问题是:
每次启动后某些网卡的名称(eth号)是随机变化的。
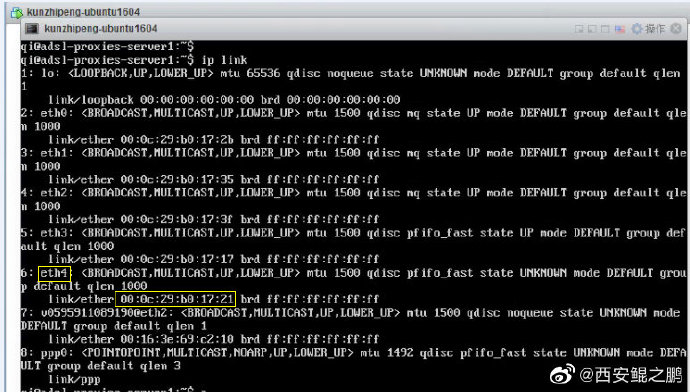
如图1和图2所示,同一块网卡"00:0c:29:b0:17:21",在第一张图中被命名为eth4,但重启后在第二张图中却被命名为eth3。
而拨号系统内不同的ADSL账号绑定着固定的网卡名称,如果eth号老是跳,就会拨到错误的Bas里,导致拨号失败。
解决方法:
给特定的MAC地址设置固定的网卡名称。
编辑/etc/udev/rules.d/70-persistent-net.rules文件:
加入:
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:0c:29:b0:17:2b", ATTR{type}=="1", KERNEL=="eth*", NAME="eth0"
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:0c:29:b0:17:35", ATTR{type}=="1", KERNEL=="eth*", NAME="eth1"
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:0c:29:b0:17:3f", ATTR{type}=="1", KERNEL=="eth*", NAME="eth2"
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:0c:29:b0:17:17", ATTR{type}=="1", KERNEL=="eth*", NAME="eth3"
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:0c:29:b0:17:21", ATTR{type}=="1", KERNEL=="eth*", NAME="eth4"
注意:Ubuntu 16.04默认不存在该配置文件,需要先创建。
参考:https://serverfault.com/questions/610967/network-adapter-to-eth-number-mapping-for-vmware/611040 -
西安鲲之鹏
发布时间:2020-03-18 18:48:46
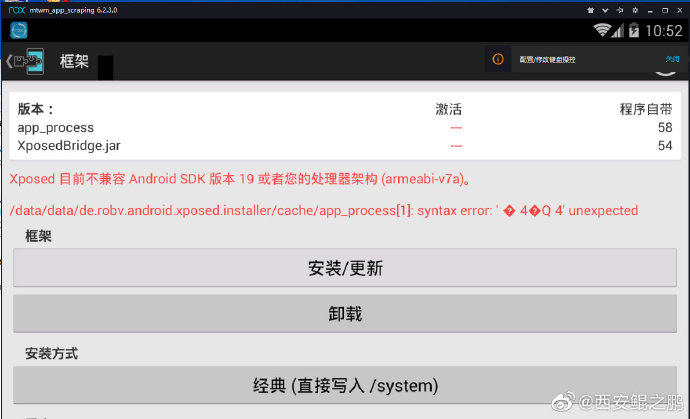
【经验分享】Nox(夜神模拟器)+ Android 4.4.2版本今天出现了一个很奇怪的问题,xposed-installer-2.6版本突然无法安装了(3月18日之前没有问题),提示信息如附图1所示(Xposed目前不兼容Android SDK版本19或者您的处理器架构)。更奇怪的是,我在其它6台机器上测试都是如此,绝不是个例。
1. 首先想到的是,它偷偷更新了。于是尝试卸载重装Nox,但是问题依旧。看了下Nox安装目录下的文件和日志,也没见有更新的迹象。
2. 会不会是在启动的时候通过网络动态加载了什么策略呢?于是尝试断掉网络,重建Nox 虚拟机,xposed-installer-2.6安装成功,在多台机器上做同样尝试,问题均解决。看来就是夜神模拟器做了手脚了。
"断网"不是长久之计,于是决定深入分析下,用wireshark抓包,主要看DNS请求,发现Nox在启动的时候访问了如下的域名:
api.bignox.com
bi.yeshen.com
app.yeshen.com
launcher.yeshen.com
res06.bignox.com
res11.bignox.com
res.yeshen.com.qingcdn.com
res.yeshen.com
pubstatus.sinaapp.com
noxagile.bceapp.com
dl.xposed.info
PS:看来小动作可真不少啊。
尝试使用dnsmasq劫持这些域名,返回127.0.0.1,果然有效。
附dnsmasq address.conf文件内容(如下),直接使用泛域名干掉所有的子域名,防止过滤的不够彻底:
address=/bignox.com/127.0.0.1
address=/yeshen.com/127.0.0.1
address=/qingcdn.com/127.0.0.1
address=/duapp.com/127.0.0.1
address=/sinaapp.com/127.0.0.1
address=/bceapp.com/127.0.0.1
address=/xposed.info/127.0.0.1
address=/duba.net/127.0.0.1
address=/bsgslb.cn/127.0.0.1
address=/applinzi.com/127.0.0.1
address=/bceapp.com/127.0.0.1
PS:为什么不直接修改hosts文件呢?一方面是机器比较多,一一设置比较麻烦,直接通过dhcp分配自定义的dns更方便。另一方面一些防护软件可能会保护hosts,设置了不一定有效。
今天时间都耗在这上面,问题总算解决了。
不好做什么评论,毕竟人家产品是免费让你用的,而且做的真心不错,再说别人坏话就不地道了。 -
西安鲲之鹏
发布时间:2020-03-17 11:45:54
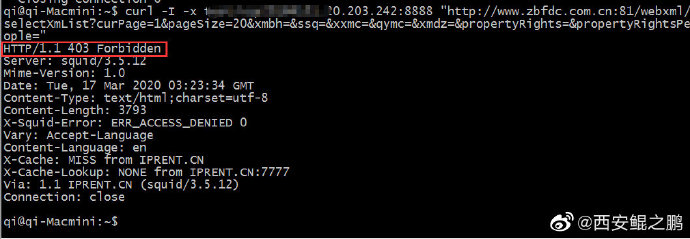
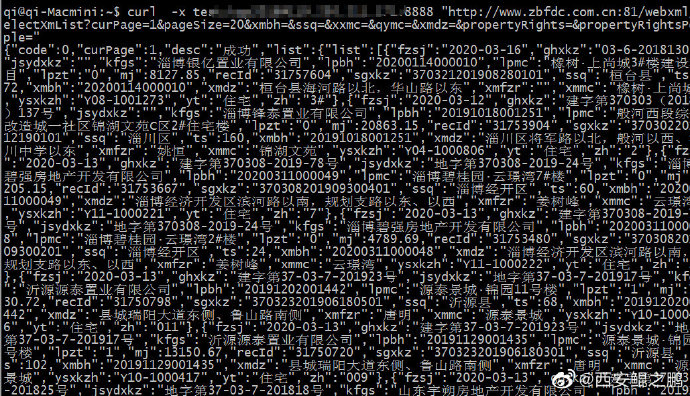
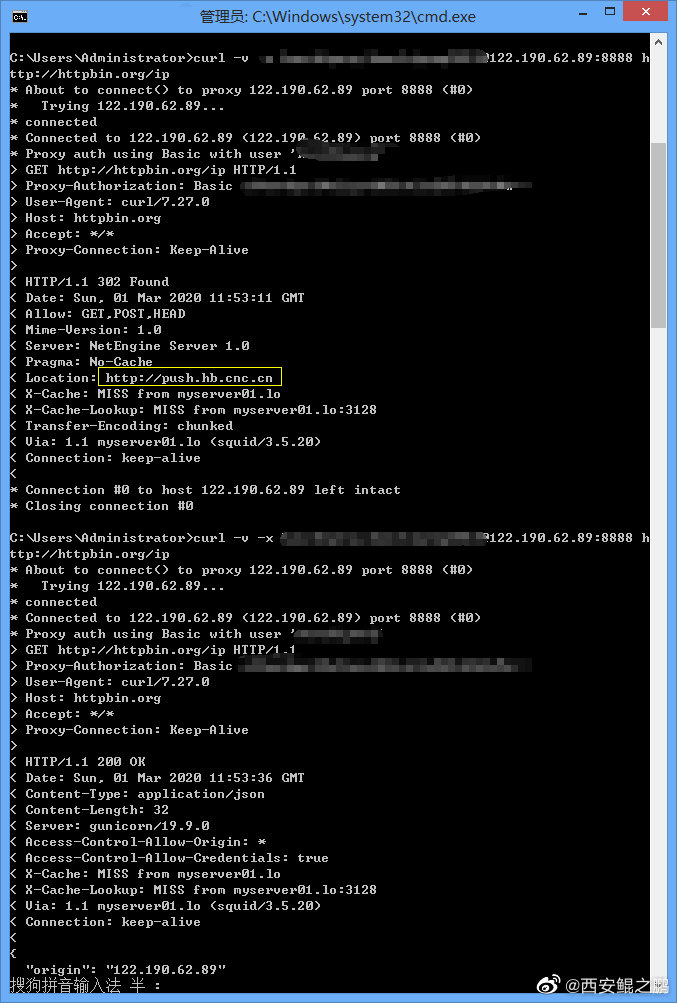
【经验分享】有客户反映使用我们的代理访问某个URL(www.zbfdc.com.cn:81)始终返回403错误,访问其它网站正常。我自己测了一下,的确如此(如附图1所示)。由于是动态IP代理,可以排除IP被封了的问题。
后来注意到,这个网站用了一个非常规的Web端口81,意识到了问题所在。
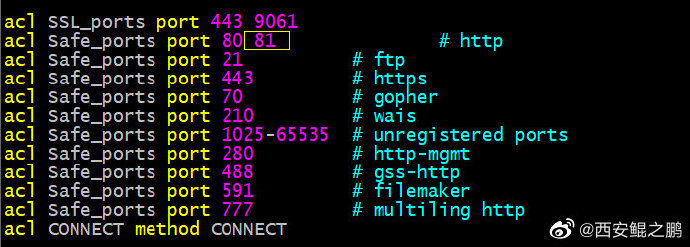
Squi默认定义了如下端口为安全端口,如果目标端口(例如本例中的81)不在其中将会被拒绝,返回403错误。
acl SSL_ports port 443
acl Safe_ports port 80 # http
acl Safe_ports port 21 # ftp
acl Safe_ports port 443 # https
acl Safe_ports port 70 # gopher
acl Safe_ports port 210 # wais
acl Safe_ports port 1025-65535 # unregistered ports
acl Safe_ports port 280 # http-mgmt
acl Safe_ports port 488 # gss-http
acl Safe_ports port 591 # filemaker
acl Safe_ports port 777 # multiling http
解决方法很简单,把81端口加入到安全端口列表中即可,如附图2所示。
重启Squid,测试,问题解决,如附图3所示。 -
西安鲲之鹏
发布时间:2020-03-12 14:05:49
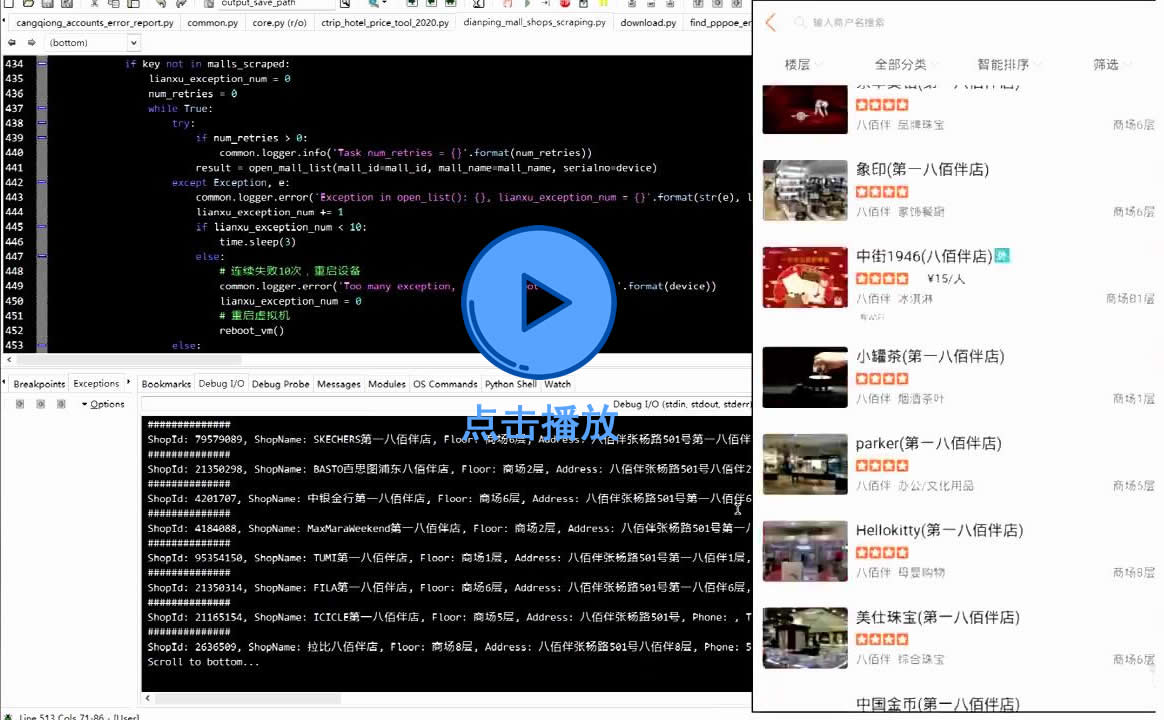
【视频演示】受客户委托,对"采集某APP内综合商场商户楼层数据"进行可行性评估。实测可行,演示如视频所示。示例数据链接:http://db.site-digger.com/csv/6469616e70696e675f6d616c6c5f73686f70735f73616d706c655f3230323030333130/ 西安鲲之鹏的微博视频
-
西安鲲之鹏
发布时间:2020-02-24 16:23:49
【经验分享】Chrome Portable各版本下载链接:https://sourceforge.mirrorservice.org/p/po/portableapps/Google%20Chrome%20Portable/?C=M;O=D,这是Chrome便携版(支持Remote Debuging,功能和安装版没有区别),最近在某爬虫项目中集成了该版本,客户不需要额外安装浏览器,用起来很省心。